
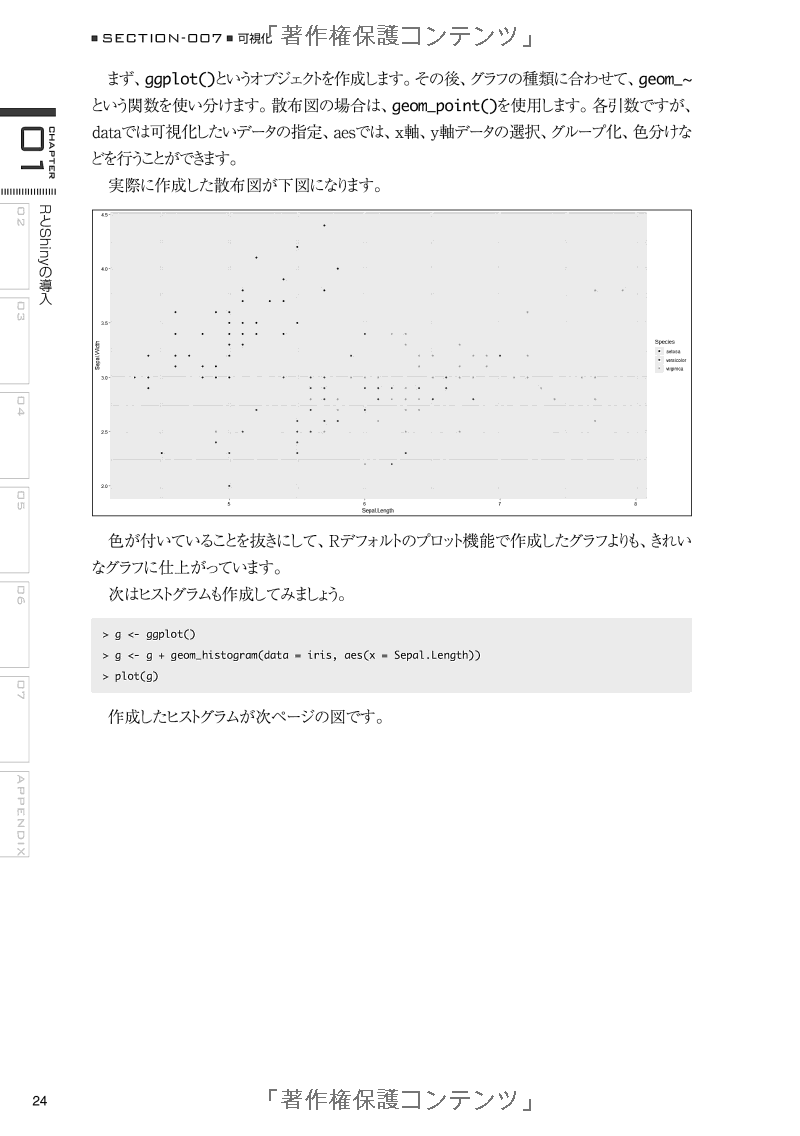
こちらでは、データ解析・統計分析などに有用なプログラミング言語「R言語」に関する人気・高評価のおすすめ本を紹介していきます。
発売したて・発売予定の新書をピックアップ
技術書は情報の鮮度も重要、人気ランキングの前に新しい書籍もチェックしておきましょう。





- 2021/07/07発売 「データサイエンスのための Rプログラミングスキル」
- 2021/11/06発売 「機械学習のためのカーネル100問 with R (機械学習の数理100問シリーズ 7)」
- 2021/12/09発売 「実践Data Scienceシリーズ ゼロからはじめるデータサイエンス入門 R・Python一挙両得」
- 2022/01/22発売 「Rでらくらくデータ分析入門 ~効率的なデータ加工のための基礎知識」
- 2022/01/26発売 「Rが生産性を高める〜データ分析ワークフロー効率化の実践」
R言語の本 人気ランキング/10冊詳細
以下が「R言語の本」人気ランキングと人気の10冊詳細です。
ランキングはAmazonの書籍売上ランキングに基づき毎日更新されています。
(2026/01/30 12:10 更新)
| Rank | 製品 | 価格 |
|---|---|---|
1 |  | |
2 |  | |
3 |  改訂2版 RユーザのためのRStudio[実践]入門〜tidyverseによるモダンな分析フローの世界... 発売日 2021/05/31 松村 優哉, 湯谷 啓明, 紀ノ定 保礼, 前田 和寛 (技術評論社) 総合評価 | |
4 |  | |
5 |  | |
6 |  | |
7 |  | |
8 |  | |
9 |  | |
10 |  |
Rによる多変量解析入門 データ分析の実践と理論

多変量解析手法の理論と実践をバランスよく習得できる!
様々な媒体、経路を通じて大規模データが、驚くほど低コストで入手できるようになった現在、多変量解析手法に習熟したデータサイエンティストに対する学術界、ビジネス界からのニーズは非常に高まっており、これに対して大学や企業では、高いデータ解析力を持った人材の育成に注力し始めています。しかし、多くの多変量解析についての学習書は、理論的な説明に終始し、実務場面でどのように利用されているかについて、殆ど配慮がない野が現状です。
そこで本書は、多変量解析手法の理論と実践をバランスよく解説することで、統計が得意ではない大学生や実務者にも利用しやすい構成とし、本書1冊で多変量解析手法を実務に応用できるまで習得できる内容となっています。
様々な媒体、経路を通じて大規模データが、驚くほど低コストで入手できるようになった現在、多変量解析手法に習熟したデータサイエンティストに対する学術界、ビジネス界からのニーズは非常に高まっており、これに対して大学や企業では、高いデータ解析力を持った人材の育成に注力し始めています。しかし、多くの多変量解析についての学習書は、理論的な説明に終始し、実務場面でどのように利用されているかについて、殆ど配慮がない野が現状です。
そこで本書は、多変量解析手法の理論と実践をバランスよく解説することで、統計が得意ではない大学生や実務者にも利用しやすい構成とし、本書1冊で多変量解析手法を実務に応用できるまで習得できる内容となっています。
内容サンプル


目次
第Ⅰ部 多変量解析入門
第1章 Rによる多変量データの基本的な統計処理
第2章 Rによるデータハンドリング
第Ⅱ部 量的変数の予測
第3章 どの要因が影響しているのかが知りたい①―重回帰分析―
第4章 どの要因が影響しているのかが知りたい②―階層的重回帰分析―
第5章 様々な集団から得られたデータを分析したい―マルチレベルモデル―
第6章 複雑な統計的仮説を統計モデルとして表したい① ―パス解析―
第Ⅲ部 尺度の分析
第7章 尺度を科学的に開発したい―探索的因子分析―
第8章 尺度を科学的に開発したい―確認的因子分析―
第9章 複雑な統計的仮説を統計モデルとして表したい② ―潜在変数を伴うパス解析―
第Ⅳ部 質的変数の予測
第10章 クロス集計表をもっと丁寧に分析したい―対数線形モデル―
第11章 質的結果を予測したい―ロジスティック回帰分析―
第Ⅴ部 個体と変数の分類
第12章 傾向が似ているものを分類したい―クラスタ―分析―
第13章 質的変数間の連関を視覚化したい―コレスポンデンス分析―
第Ⅵ部 多変量解析を使いこなす
第14章 多変量データのもつ情報を効率的に可視化したい
第15章 多変量解析手法を実践で生かすために
第1章 Rによる多変量データの基本的な統計処理
第2章 Rによるデータハンドリング
第Ⅱ部 量的変数の予測
第3章 どの要因が影響しているのかが知りたい①―重回帰分析―
第4章 どの要因が影響しているのかが知りたい②―階層的重回帰分析―
第5章 様々な集団から得られたデータを分析したい―マルチレベルモデル―
第6章 複雑な統計的仮説を統計モデルとして表したい① ―パス解析―
第Ⅲ部 尺度の分析
第7章 尺度を科学的に開発したい―探索的因子分析―
第8章 尺度を科学的に開発したい―確認的因子分析―
第9章 複雑な統計的仮説を統計モデルとして表したい② ―潜在変数を伴うパス解析―
第Ⅳ部 質的変数の予測
第10章 クロス集計表をもっと丁寧に分析したい―対数線形モデル―
第11章 質的結果を予測したい―ロジスティック回帰分析―
第Ⅴ部 個体と変数の分類
第12章 傾向が似ているものを分類したい―クラスタ―分析―
第13章 質的変数間の連関を視覚化したい―コレスポンデンス分析―
第Ⅵ部 多変量解析を使いこなす
第14章 多変量データのもつ情報を効率的に可視化したい
第15章 多変量解析手法を実践で生かすために
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
川端一光(カワハシイッコウ)
2008年早稲田大学大学院文学研究科博士後期課程単位取得退学、博士(文学)。現在、明治学院大学心理学部准教授。専門、心理統計学・教育測定学
岩間徳兼(イワマノリカズ)
2011年早稲田大学大学院文学研究科博士後期課程修了、博士(文学)。現在、北海道大学高等教育推進機構講師。専門、心理統計学・教育測定学
鈴木雅之(スズキマサユキ)
2013年東京大学大学院教育学研究科博士課程修了、博士(教育学)。現在、横浜国立大学教育学部准教授。専門、教育心理学(本データはこの書籍が刊行された当時に掲載されていたものです)
2008年早稲田大学大学院文学研究科博士後期課程単位取得退学、博士(文学)。現在、明治学院大学心理学部准教授。専門、心理統計学・教育測定学
岩間徳兼(イワマノリカズ)
2011年早稲田大学大学院文学研究科博士後期課程修了、博士(文学)。現在、北海道大学高等教育推進機構講師。専門、心理統計学・教育測定学
鈴木雅之(スズキマサユキ)
2013年東京大学大学院教育学研究科博士課程修了、博士(教育学)。現在、横浜国立大学教育学部准教授。専門、教育心理学(本データはこの書籍が刊行された当時に掲載されていたものです)
↓全て表示↑少なく表示
R言語ではじめるプログラミングとデータ分析

R言語によるデータ分析をはじめてみよう!
この本は、初心者向けのR言語の入門書です。
R言語はデータ分析に秀でたプログラミング言語です。もちろん無料で使えます。
この本では、R言語の初歩と、データ分析の基本を解説しています。
Tidyverseと呼ばれる「データ分析の生産性を上げてくれる便利なパッケージ群」の解説もしています。
【特徴】
・基礎から順にステップアップするので、初心者でも読みやすい
・「3行で終わる短いプログラミング事例」を豊富に紹介
・難易度マークがついているので、難しい箇所は飛ばしながら読める
・巻末にRリファレンスがついているので、読み返しやすい
【内容】
第1部【導入編】Rを始める
第2部【初級編】Rによるデータ分析の基本
第3部【中級編】長いコードを書く技術
第4部【応用編】Tidyverseの活用
参考文献
索引
Rリファレンス
この本は、初心者向けのR言語の入門書です。
R言語はデータ分析に秀でたプログラミング言語です。もちろん無料で使えます。
この本では、R言語の初歩と、データ分析の基本を解説しています。
Tidyverseと呼ばれる「データ分析の生産性を上げてくれる便利なパッケージ群」の解説もしています。
【特徴】
・基礎から順にステップアップするので、初心者でも読みやすい
・「3行で終わる短いプログラミング事例」を豊富に紹介
・難易度マークがついているので、難しい箇所は飛ばしながら読める
・巻末にRリファレンスがついているので、読み返しやすい
【内容】
第1部【導入編】Rを始める
第2部【初級編】Rによるデータ分析の基本
第3部【中級編】長いコードを書く技術
第4部【応用編】Tidyverseの活用
参考文献
索引
Rリファレンス
目次
■第1部 【導入編】Rを始める
第1章 Rプログラミングの考え方
第2章 Rを始める
■第2部 【初級編】Rによるデータ分析の基本
[プログラミングの体験]
第1章 データ分析を体験する
第2章 3行プログラミングを構成する要素
[データの取り扱いの基本]
第3章 データの型
第4章 ベクトル・行列・配列
第5章 データフレーム
第6章 いろいろなデータ構造の使い分け
第7章 入出力
[様々な計算・分析処理の事例]
第8章 演算子と論理演算
第9章 3行以下で終わる分析の例:集計編
第10章 3行以下で終わる分析の例:変換編
第11章 3行以下で終わる分析の例:可視化編
第12章 確率分布
第13章 3行以下で終わる分析の例:推測統計編
第14章 外部パッケージの活用
■第3部 【中級編】長いコードを書く技術
[環境構築]
第1章 Gitによるバージョン管理
[Rの構文の理解]
第2章 条件分岐と繰り返し
第3章 関数の作成と関数の活用
第4章 関数の応用的な使い方
[実装時の工夫]
第5章 長いコードを書くときの工夫
■第4部 【応用編】Tidyverseの活用
[導入]
第1章 Tidyverseの基本
[Tidyverseによるデータ処理]
第2章 パイプ演算子
第3章 データの読み込み
第4章 データの抽出・変換・集計
第5章 日付の操作
第6章 データの可視化
第7章 データの整形と結合
参考文献
索引
Rリファレンス
第1章 Rプログラミングの考え方
第2章 Rを始める
■第2部 【初級編】Rによるデータ分析の基本
[プログラミングの体験]
第1章 データ分析を体験する
第2章 3行プログラミングを構成する要素
[データの取り扱いの基本]
第3章 データの型
第4章 ベクトル・行列・配列
第5章 データフレーム
第6章 いろいろなデータ構造の使い分け
第7章 入出力
[様々な計算・分析処理の事例]
第8章 演算子と論理演算
第9章 3行以下で終わる分析の例:集計編
第10章 3行以下で終わる分析の例:変換編
第11章 3行以下で終わる分析の例:可視化編
第12章 確率分布
第13章 3行以下で終わる分析の例:推測統計編
第14章 外部パッケージの活用
■第3部 【中級編】長いコードを書く技術
[環境構築]
第1章 Gitによるバージョン管理
[Rの構文の理解]
第2章 条件分岐と繰り返し
第3章 関数の作成と関数の活用
第4章 関数の応用的な使い方
[実装時の工夫]
第5章 長いコードを書くときの工夫
■第4部 【応用編】Tidyverseの活用
[導入]
第1章 Tidyverseの基本
[Tidyverseによるデータ処理]
第2章 パイプ演算子
第3章 データの読み込み
第4章 データの抽出・変換・集計
第5章 日付の操作
第6章 データの可視化
第7章 データの整形と結合
参考文献
索引
Rリファレンス
↓全て表示↑少なく表示
Users Voice
著者略歴
馬場真哉(ババシンヤ)
2014年北海道大学水産科学院修了。Logics of BlueというWebサイトの管理人(本データはこの書籍が刊行された当時に掲載されていたものです)
2014年北海道大学水産科学院修了。Logics of BlueというWebサイトの管理人(本データはこの書籍が刊行された当時に掲載されていたものです)
改訂2版 RユーザのためのRStudio[実践]入門〜tidyverseによるモダンな分析フローの世界

改訂2版 RユーザのためのRStudio[実践]入門〜tidyverseによるモダンな分析フローの世界
(著)松村 優哉, 湯谷 啓明, 紀ノ定 保礼, 前田 和寛
発売日 2021/05/31
(著)松村 優哉, 湯谷 啓明, 紀ノ定 保礼, 前田 和寛
発売日 2021/05/31
総合評価
(2026/01/30 12:10時点)
(概要)
2018年に刊行した通称「#宇宙本」を最新の情報に改訂!
本書は、R言語のIDEであるRStudioと、モダンなデータ分析を実現するtidyverseパッケージの入門書です。RStudioの基本機能からはじまり、Rによるデータの収集(2章)、データの整形(3章)、可視化(4章)、レポーティング(5章)といったデータ分析ワークフローの各プロセスの基礎を押さえることができます。
RStudio v1.4に対応し、新たに追加されたVisual Editor機能やRStudio v1.2で追加された「Jobs機能」などを紹介します。また、dplyr 1.0に対応し、データ処理系の関数の解説を追加しています。さらに改訂版では付録として、「stringrによる文字列データの処理」「lubridateによる日付・時刻データの処理」の2章を追加しています。
さまざまな機能が追加されていくRStudioとtidyverseに触れ、モダンなデータ分析をはじめましょう!
(こんな方におすすめ)
・R / RStudioでモダンな分析環境を手にしたい方
・分析フローを意識した業務/解析をしたい方
(目次)
第1章 RStudioの基礎
1-1 RStudioのダウンロードとインストール
1-2 RStudioの基本操作
1-3 RStudioを自分好みにカスタマイズ
1-4 ファイルの読み込み
1-5 RやRStudioで困ったときは
1-6 まとめ
第2章 スクレイピングによるデータ収集
2-1 なぜスクレイピングが必要か
2-2 スクレイピングに必要なWeb知識
2-3 Rによるスクレイピング入門
2-4 API
2-5 まとめ
第3章 dplyr/tidyrによるデータ前処理
3-1 tidy dataとは
3-2 tidyrによるtidy dataへの変形
3-3 dplyrによる基本的なデータ操作
3-4 dplyrによる応用的なデータ操作
3-5 dplyrによる2つのデータセットの結合と絞り込み
3-6 tidyrのその他の関数
3-7 まとめ
第4章 ggplot2を用いたデータ可視化
4-1 可視化の重要性
4-2 ggplot2パッケージを用いた可視化
4-3 他者と共有可能な状態に仕上げる
4-4 便利なパッケージ
4-5 まとめ
第5章 R Markdownによるレポート生成
5-1 分析結果のレポーティング
5-2 R Markdown入門
5-3 出力形式
5-4 まとめ
付録A stringrによる文字列データの処理
A-1 文字列データとstringrパッケージ
A-2 文字列処理の例
A-3 正規表現
A-4 まとめ
付録B lubridateによる日付・時刻データの処理2
B-1 日付・時刻のデータ型とlubridateパッケージ
B-2 日付・時刻への変換
B-3 日付・時刻データの加工
B-4 interval
B-5 日付、時刻データの計算・集計例
B-6 タイムゾーンの扱い
B-7 その他の日付・時刻データ処理に関する関数
2018年に刊行した通称「#宇宙本」を最新の情報に改訂!
本書は、R言語のIDEであるRStudioと、モダンなデータ分析を実現するtidyverseパッケージの入門書です。RStudioの基本機能からはじまり、Rによるデータの収集(2章)、データの整形(3章)、可視化(4章)、レポーティング(5章)といったデータ分析ワークフローの各プロセスの基礎を押さえることができます。
RStudio v1.4に対応し、新たに追加されたVisual Editor機能やRStudio v1.2で追加された「Jobs機能」などを紹介します。また、dplyr 1.0に対応し、データ処理系の関数の解説を追加しています。さらに改訂版では付録として、「stringrによる文字列データの処理」「lubridateによる日付・時刻データの処理」の2章を追加しています。
さまざまな機能が追加されていくRStudioとtidyverseに触れ、モダンなデータ分析をはじめましょう!
(こんな方におすすめ)
・R / RStudioでモダンな分析環境を手にしたい方
・分析フローを意識した業務/解析をしたい方
(目次)
第1章 RStudioの基礎
1-1 RStudioのダウンロードとインストール
1-2 RStudioの基本操作
1-3 RStudioを自分好みにカスタマイズ
1-4 ファイルの読み込み
1-5 RやRStudioで困ったときは
1-6 まとめ
第2章 スクレイピングによるデータ収集
2-1 なぜスクレイピングが必要か
2-2 スクレイピングに必要なWeb知識
2-3 Rによるスクレイピング入門
2-4 API
2-5 まとめ
第3章 dplyr/tidyrによるデータ前処理
3-1 tidy dataとは
3-2 tidyrによるtidy dataへの変形
3-3 dplyrによる基本的なデータ操作
3-4 dplyrによる応用的なデータ操作
3-5 dplyrによる2つのデータセットの結合と絞り込み
3-6 tidyrのその他の関数
3-7 まとめ
第4章 ggplot2を用いたデータ可視化
4-1 可視化の重要性
4-2 ggplot2パッケージを用いた可視化
4-3 他者と共有可能な状態に仕上げる
4-4 便利なパッケージ
4-5 まとめ
第5章 R Markdownによるレポート生成
5-1 分析結果のレポーティング
5-2 R Markdown入門
5-3 出力形式
5-4 まとめ
付録A stringrによる文字列データの処理
A-1 文字列データとstringrパッケージ
A-2 文字列処理の例
A-3 正規表現
A-4 まとめ
付録B lubridateによる日付・時刻データの処理2
B-1 日付・時刻のデータ型とlubridateパッケージ
B-2 日付・時刻への変換
B-3 日付・時刻データの加工
B-4 interval
B-5 日付、時刻データの計算・集計例
B-6 タイムゾーンの扱い
B-7 その他の日付・時刻データ処理に関する関数
↓全て表示↑少なく表示
内容サンプル


目次
はじめに
本書の特徴
本書の構成
本書の対象読者
本書で解説しなかったこと
さあRStudioで分析を
tidyverseとは
tidyverseのパッケージ
tidyverseの過去
tidyverseの未来
第1章 RStudioの基礎
1-1 RStudioのダウンロードとインストール
macOS
Windows
1-2 RStudioの基本操作
RStudioのインターフェース
プロジェクト機能
Rスクリプトの新規作成と保存
Rのコマンドの実行
オブジェクトの確認
補完機能
Jobs機能
1-3 RStudioを自分好みにカスタマイズ
RStudio全般
コーディング
外観
Terminal
キーボードショートカット
1-4 ファイルの読み込み
Rの標準関数の問題点
readrパッケージ
Excelファイルの読み込み
SAS,SPSS,STATAファイルの読み込み
RStudio(GUI)によるデータの読み込み
ファイル読み込みのまとめ
1-5 RやRStudioで困ったときは
ヘルプを使う
Vignetteを見る
チートシートを使う
コマンドパレット
1-6 まとめ
第2章 スクレイピングによるデータ収集
2-1 なぜスクレイピングが必要か
スクレイピングとは
手作業によるデータ取得の限界
2-2 スクレイピングに必要なWeb知識
HTML
CSS
XMLとXPath
2-3 Rによるスクレイピング入門
rvestパッケージ
Webページタイトルの抽出
パイプ演算子
スクレイピング実践
2-4 API
APIとは
rtweetパッケージによるTwitterデータの収集
ツイートの収集
COLUMN ブラウザの自動操作
COLUMN Webスクレイピングをするときの注意点
2-5 まとめ
参考文献
第3章 dplyr/tidyrによるデータ前処理
3-1 tidy dataとは
tidy dataの定義
tidyではないデータ
3-2 tidyrによるtidy dataへの変形
tidyではないデータ
pivot_longer()による縦長データへの変形
pivot_wider()による横長のデータへの変形
3-3 dplyrによる基本的なデータ操作
tibbleとデータフレームの違い
dplyrの関数の概要
1つのデータフレームを操作する関数の共通点と%>%
演算子による処理のパイプライン化
filter()による行の絞り込み
COLUMN dplyrの関数内でのコード実行
arrange()によるデータの並び替え
select()による列の絞り込み
relocate()による列の並べ替え
mutate()による列の追加
summarise()によるデータの集計計算
3-4 dplyrによる応用的なデータ操作
グループ化
COLUMN 複数の値を返す集約関数とsummarise()
COLUMN ウィンドウ関数
COLUMN selectのセマンティクスとmutateのセマンティクス
複数の列への操作
3-5 dplyrによる2つのデータセットの結合と絞り込み
inner_join()によるデータの結合
さまざまなキーの指定方法
inner_join()以外の関数によるデータの結合
semi_join()、anti_join()による絞り込み
3-6 tidyrのその他の関数
separate()による値の分割
extract()による値の抽出
separate_rows()による値の分割(縦方向)
暗黙の欠損値
complete()による存在しない組み合わせの検出
COLUMN group_by()による存在しない組み合わせの表示
fill()による欠損値の補完
replace_na()による欠損値の置き換え
3-7 まとめ
第4章 ggplot2を用いたデータ可視化
4-1 可視化の重要性
4-2 ggplot2パッケージを用いた可視化
準備
エステティックマッピング
COLUMN グラフに肉付けする
統計的処理:stat
COLUMN X軸に離散変数をマッピングした場合における折れ線グラフ
配置の指定:position
COLUMN position_dodge()とposition_dodge2()
軸の調整
グラフの保存
4-3 他者と共有可能な状態に仕上げる
themeの変更
文字サイズやフォントの変更
配色の変更
ラベルを変更する
4-4 便利なパッケージ
複数のグラフを並べる
表示される水準の順番を変更したい
4-5 まとめ
参考文献
第5章 R Markdownによるレポート生成
5-1 分析結果のレポーティング
ドキュメント作成の現場
手作業によるドキュメント作成の問題点
5-2 R Markdown入門
Hello, R Markdown
Rmdファイルと処理フロー
Markdownの基本
Rチャンク
ドキュメントの設定
RStudioで使える便利なTips
COLUMN Visual ModeによるRmdファイルの編集
5-3 出力形式
html_document形式
pdf_document形式
word_document形式
スライド出力
R Markdownの出力形式を提供するパッケージ
COLUMN 日本語環境での注意点
5-4 まとめ
参考URL・参考文献
付録A stringrによる文字列データの処理
A-1 文字列データとstringrパッケージ
A-2 文字列処理の例
str_c()による文字列の連結
str_split()による文字列の分割
str_detect()による文字列の判定
COLUMN fixed()/coll()を用いた挙動の調整
str_count()による検索対象の計上
str_locate()による検索対象の位置の特定
str_subset()/str_extract()による文字列の抽出
str_sub()による文字列の抽出
str_replace()による文字列の置換
str_trim()/str_squish()による空白の除去
A-3 正規表現
任意の文字や記号の検索
高度な検索
regex()
A-4 まとめ
付録B lubridateによる日付・時刻データの処理2
B-1 日付・時刻のデータ型とlubridateパッケージ
B-2 日付・時刻への変換
文字列から日付・時刻への変換
数値から日付・時刻への変換
readrパッケージによる読み込み時の変換
B-3 日付・時刻データの加工
B-4 interval
B-5 日付、時刻データの計算・集計例
wday()を使った曜日の計算例
floor_date()を使った週ごとの集計例
B-6 タイムゾーンの扱い
B-7 その他の日付・時刻データ処理に関する関数
zipanguパッケージ
sliderパッケージ
本書の特徴
本書の構成
本書の対象読者
本書で解説しなかったこと
さあRStudioで分析を
tidyverseとは
tidyverseのパッケージ
tidyverseの過去
tidyverseの未来
第1章 RStudioの基礎
1-1 RStudioのダウンロードとインストール
macOS
Windows
1-2 RStudioの基本操作
RStudioのインターフェース
プロジェクト機能
Rスクリプトの新規作成と保存
Rのコマンドの実行
オブジェクトの確認
補完機能
Jobs機能
1-3 RStudioを自分好みにカスタマイズ
RStudio全般
コーディング
外観
Terminal
キーボードショートカット
1-4 ファイルの読み込み
Rの標準関数の問題点
readrパッケージ
Excelファイルの読み込み
SAS,SPSS,STATAファイルの読み込み
RStudio(GUI)によるデータの読み込み
ファイル読み込みのまとめ
1-5 RやRStudioで困ったときは
ヘルプを使う
Vignetteを見る
チートシートを使う
コマンドパレット
1-6 まとめ
第2章 スクレイピングによるデータ収集
2-1 なぜスクレイピングが必要か
スクレイピングとは
手作業によるデータ取得の限界
2-2 スクレイピングに必要なWeb知識
HTML
CSS
XMLとXPath
2-3 Rによるスクレイピング入門
rvestパッケージ
Webページタイトルの抽出
パイプ演算子
スクレイピング実践
2-4 API
APIとは
rtweetパッケージによるTwitterデータの収集
ツイートの収集
COLUMN ブラウザの自動操作
COLUMN Webスクレイピングをするときの注意点
2-5 まとめ
参考文献
第3章 dplyr/tidyrによるデータ前処理
3-1 tidy dataとは
tidy dataの定義
tidyではないデータ
3-2 tidyrによるtidy dataへの変形
tidyではないデータ
pivot_longer()による縦長データへの変形
pivot_wider()による横長のデータへの変形
3-3 dplyrによる基本的なデータ操作
tibbleとデータフレームの違い
dplyrの関数の概要
1つのデータフレームを操作する関数の共通点と%>%
演算子による処理のパイプライン化
filter()による行の絞り込み
COLUMN dplyrの関数内でのコード実行
arrange()によるデータの並び替え
select()による列の絞り込み
relocate()による列の並べ替え
mutate()による列の追加
summarise()によるデータの集計計算
3-4 dplyrによる応用的なデータ操作
グループ化
COLUMN 複数の値を返す集約関数とsummarise()
COLUMN ウィンドウ関数
COLUMN selectのセマンティクスとmutateのセマンティクス
複数の列への操作
3-5 dplyrによる2つのデータセットの結合と絞り込み
inner_join()によるデータの結合
さまざまなキーの指定方法
inner_join()以外の関数によるデータの結合
semi_join()、anti_join()による絞り込み
3-6 tidyrのその他の関数
separate()による値の分割
extract()による値の抽出
separate_rows()による値の分割(縦方向)
暗黙の欠損値
complete()による存在しない組み合わせの検出
COLUMN group_by()による存在しない組み合わせの表示
fill()による欠損値の補完
replace_na()による欠損値の置き換え
3-7 まとめ
第4章 ggplot2を用いたデータ可視化
4-1 可視化の重要性
4-2 ggplot2パッケージを用いた可視化
準備
エステティックマッピング
COLUMN グラフに肉付けする
統計的処理:stat
COLUMN X軸に離散変数をマッピングした場合における折れ線グラフ
配置の指定:position
COLUMN position_dodge()とposition_dodge2()
軸の調整
グラフの保存
4-3 他者と共有可能な状態に仕上げる
themeの変更
文字サイズやフォントの変更
配色の変更
ラベルを変更する
4-4 便利なパッケージ
複数のグラフを並べる
表示される水準の順番を変更したい
4-5 まとめ
参考文献
第5章 R Markdownによるレポート生成
5-1 分析結果のレポーティング
ドキュメント作成の現場
手作業によるドキュメント作成の問題点
5-2 R Markdown入門
Hello, R Markdown
Rmdファイルと処理フロー
Markdownの基本
Rチャンク
ドキュメントの設定
RStudioで使える便利なTips
COLUMN Visual ModeによるRmdファイルの編集
5-3 出力形式
html_document形式
pdf_document形式
word_document形式
スライド出力
R Markdownの出力形式を提供するパッケージ
COLUMN 日本語環境での注意点
5-4 まとめ
参考URL・参考文献
付録A stringrによる文字列データの処理
A-1 文字列データとstringrパッケージ
A-2 文字列処理の例
str_c()による文字列の連結
str_split()による文字列の分割
str_detect()による文字列の判定
COLUMN fixed()/coll()を用いた挙動の調整
str_count()による検索対象の計上
str_locate()による検索対象の位置の特定
str_subset()/str_extract()による文字列の抽出
str_sub()による文字列の抽出
str_replace()による文字列の置換
str_trim()/str_squish()による空白の除去
A-3 正規表現
任意の文字や記号の検索
高度な検索
regex()
A-4 まとめ
付録B lubridateによる日付・時刻データの処理2
B-1 日付・時刻のデータ型とlubridateパッケージ
B-2 日付・時刻への変換
文字列から日付・時刻への変換
数値から日付・時刻への変換
readrパッケージによる読み込み時の変換
B-3 日付・時刻データの加工
B-4 interval
B-5 日付、時刻データの計算・集計例
wday()を使った曜日の計算例
floor_date()を使った週ごとの集計例
B-6 タイムゾーンの扱い
B-7 その他の日付・時刻データ処理に関する関数
zipanguパッケージ
sliderパッケージ
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
↓全て表示↑少なく表示
Rによるテキストマイニング入門(第2版)

フリーの環境を使い,実践しながらひと通りの手法を学べる入門書です.ネット上にあふれる膨大なテキストデータを効率よく収集・分析する方法や,アンケート結果をデータに置き換えて分析する方法を紹介します.
初心者はもちろん,さまざまな手法を知りたいという読者にもおすすめです.
〈おすすめポイント〉
・基本的な手法のほか,ウェブスクレイピングやトピックモデルといった,最近注目の技術も紹介.
・ネットワークグラフ,ワードクラウドなどの可視化機能をふんだんに利用.データの特徴をつかむのに役立つ.
・実践には統合環境RStudioを導入.RStudioでは,マウスによる直感的な操作ができ,コードの補完機能などもあるので,簡単・快適に作業をすることが可能.
テキストマイニングの定番書を, Rのバージョンアップや新機能に対応して大幅にリニューアルしたものです.さらに使いやすく,充実した内容となっています.
【目次】
第1章 テキストマイニングとは何か
1.1 データマイニングとテキストマイニング
1.2 応用事例
1.3 日本語処理
1.4 データ解析のツール
第2章 テキストマイニングの準備
2.1 R のインストール
2.2 RStudio の導入
2.3 MeCab の導入
2.4 MeCab のインストール
2.5 MeCab の実行
2.6 RMeCab の導入
2.7 MeCab の辞書整備
第3章 R/RStudio 速習
3.1 プロジェクト
3.2 起動から終了まで
3.3 R におけるデータの基本型
3.4 ベクトル
3.5 関数
3.6 データフレーム
3.7 CSV ファイルの読み込み
3.8 データフレームの操作(添字)
3.9 リスト
3.10 リストの繰り返し処理
3.11 行列
3.12 パイプ処理
3.13 データフレームを操作する主な関数
3.14 制御構文
3.15 関数の作成
3.16 その他,便利な関数
3.17 グラフィックス
第4章 文字処理と正規表現
4.1 文字データの検索・置換
4.2 stringr パッケージによる処理
4.3 正規表現で使われる記法
4.4 tm パッケージ
4.5 単語文書行列の生成
第5章 RMeCab によるテキスト解析
5.1 RMeCab パッケージ
5.2 短いテキストの解析
5.3 MeCab の解析出力をすべて取り込む方法
5.4 頻度表の作成と利用
5.5 単語文書行列の生成
5.6 N グラムのデータフレームの生成
5.7 関数一覧
第6章 口コミのテキストマイニング—ウェブスクレイピング
6.1 SNS からのスクレイピング
6.2 ウェブスクレイピングの準備
6.3 バイグラムとネットワークグラフ
第7章 アンケート自由記述文の分析—対応分析
7.1 沖縄観光への意見データ
7.2 アンケート自由記述文のデータ整形
7.3 意見データの対応分析
7.4 独立性の検定(カイ自乗検定)
7.5 対応分析
第8章 青空文庫データの解析—ワードクラウドとネットワークグラフ
8.1 ダウンロードしたファイルの整形と解析
8.2 ネットワークグラフ
第9章 テキストの分類—クラスター分析,トピックモデル
9.1 解析の準備
9.2 クラスター分析
9.3 所信表明演説のクラスター分析
9.4 潜在的意味インデキシング
9.5 特異値分解
9.6 潜在的意味インデキシングによる分類
9.7 トピックモデル
第10章 書き手の判別—漱石と鴎外の文体比較
10.1 分析テキスト
10.2 N グラムを利用したクラスター分析
10.3 書き手の癖
10.4 主成分分析
10.5 主成分分析による作家の判別
第11章 Twitter タイムラインの分析—API の利用
11.1 Twitter API の利用
11.2 R での準備
11.3 twitteR の利用
11.4 特定のアカウントのツイートを取得
11.5 トレンドの取得
参考文献
索 引
初心者はもちろん,さまざまな手法を知りたいという読者にもおすすめです.
〈おすすめポイント〉
・基本的な手法のほか,ウェブスクレイピングやトピックモデルといった,最近注目の技術も紹介.
・ネットワークグラフ,ワードクラウドなどの可視化機能をふんだんに利用.データの特徴をつかむのに役立つ.
・実践には統合環境RStudioを導入.RStudioでは,マウスによる直感的な操作ができ,コードの補完機能などもあるので,簡単・快適に作業をすることが可能.
テキストマイニングの定番書を, Rのバージョンアップや新機能に対応して大幅にリニューアルしたものです.さらに使いやすく,充実した内容となっています.
【目次】
第1章 テキストマイニングとは何か
1.1 データマイニングとテキストマイニング
1.2 応用事例
1.3 日本語処理
1.4 データ解析のツール
第2章 テキストマイニングの準備
2.1 R のインストール
2.2 RStudio の導入
2.3 MeCab の導入
2.4 MeCab のインストール
2.5 MeCab の実行
2.6 RMeCab の導入
2.7 MeCab の辞書整備
第3章 R/RStudio 速習
3.1 プロジェクト
3.2 起動から終了まで
3.3 R におけるデータの基本型
3.4 ベクトル
3.5 関数
3.6 データフレーム
3.7 CSV ファイルの読み込み
3.8 データフレームの操作(添字)
3.9 リスト
3.10 リストの繰り返し処理
3.11 行列
3.12 パイプ処理
3.13 データフレームを操作する主な関数
3.14 制御構文
3.15 関数の作成
3.16 その他,便利な関数
3.17 グラフィックス
第4章 文字処理と正規表現
4.1 文字データの検索・置換
4.2 stringr パッケージによる処理
4.3 正規表現で使われる記法
4.4 tm パッケージ
4.5 単語文書行列の生成
第5章 RMeCab によるテキスト解析
5.1 RMeCab パッケージ
5.2 短いテキストの解析
5.3 MeCab の解析出力をすべて取り込む方法
5.4 頻度表の作成と利用
5.5 単語文書行列の生成
5.6 N グラムのデータフレームの生成
5.7 関数一覧
第6章 口コミのテキストマイニング—ウェブスクレイピング
6.1 SNS からのスクレイピング
6.2 ウェブスクレイピングの準備
6.3 バイグラムとネットワークグラフ
第7章 アンケート自由記述文の分析—対応分析
7.1 沖縄観光への意見データ
7.2 アンケート自由記述文のデータ整形
7.3 意見データの対応分析
7.4 独立性の検定(カイ自乗検定)
7.5 対応分析
第8章 青空文庫データの解析—ワードクラウドとネットワークグラフ
8.1 ダウンロードしたファイルの整形と解析
8.2 ネットワークグラフ
第9章 テキストの分類—クラスター分析,トピックモデル
9.1 解析の準備
9.2 クラスター分析
9.3 所信表明演説のクラスター分析
9.4 潜在的意味インデキシング
9.5 特異値分解
9.6 潜在的意味インデキシングによる分類
9.7 トピックモデル
第10章 書き手の判別—漱石と鴎外の文体比較
10.1 分析テキスト
10.2 N グラムを利用したクラスター分析
10.3 書き手の癖
10.4 主成分分析
10.5 主成分分析による作家の判別
第11章 Twitter タイムラインの分析—API の利用
11.1 Twitter API の利用
11.2 R での準備
11.3 twitteR の利用
11.4 特定のアカウントのツイートを取得
11.5 トレンドの取得
参考文献
索 引
↓全て表示↑少なく表示
内容サンプル


目次
第1章 テキストマイニングとは何か
第2章 テキストマイニングの準備
第3章 R/RStudio速習
第4章 文字処理と正規表現
第5章 RMeCabによるテキスト解析
第6章 口コミのテキストマイニング―ウェブスクレイピング
第7章 アンケート自由記述文の分析―対応分析
第8章 青空文庫データの解析―ワードクラウドとネットワークグラフ
第9章 テキストの分類―クラスター分析,トピックモデル
第10章 書き手の判別―漱石と鴎外の文体比較
第11章 Twitterタイムラインの分析―APIの利用
第2章 テキストマイニングの準備
第3章 R/RStudio速習
第4章 文字処理と正規表現
第5章 RMeCabによるテキスト解析
第6章 口コミのテキストマイニング―ウェブスクレイピング
第7章 アンケート自由記述文の分析―対応分析
第8章 青空文庫データの解析―ワードクラウドとネットワークグラフ
第9章 テキストの分類―クラスター分析,トピックモデル
第10章 書き手の判別―漱石と鴎外の文体比較
第11章 Twitterタイムラインの分析―APIの利用
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
Rによる 統計的学習入門

Rによる 統計的学習入門
(著)Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani
発売日 2018/08/03
(著)Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani
発売日 2018/08/03
総合評価
(2026/01/30 12:10時点)
原著タイトル:An Introduction to Statistical Learning: with Applications in R (Springer, 2013)
・フリーの統計解析ソフト「R」を使って練習問題を解きながら統計解析・機械学習を学ぶ。
・数学的な厳密さよりも,わかりやすさ,使えることを重視。
・文系を含む学部学生でも読みこなせる。
・南カリフォルニア大学ビジネススクールの人気講義のテキスト。
・原著は米Amazonでは売上順位トップクラスの人気書籍(Mathematical & Statistical分野.2018年6月現在)
・原著者は当該分野の有力者。
・対象:統計・情報・計算機科学・データサイエンス・経済・経営・金融(FinTech)などを専攻する学部学生,ビジネススクールの学生,若手研究者,実務者,ビックデータの解析を期待される担当者
ビッグデータに活用できる統計的学習を,専門外にもわかりやすくRで実践。〔内容〕導入/統計的学習/線形回帰/分類/リサンプリング法/線形モデル選択と正則化/線形を超えて/木に基づく方法/サポートベクターマシン/教師なし学習
・フリーの統計解析ソフト「R」を使って練習問題を解きながら統計解析・機械学習を学ぶ。
・数学的な厳密さよりも,わかりやすさ,使えることを重視。
・文系を含む学部学生でも読みこなせる。
・南カリフォルニア大学ビジネススクールの人気講義のテキスト。
・原著は米Amazonでは売上順位トップクラスの人気書籍(Mathematical & Statistical分野.2018年6月現在)
・原著者は当該分野の有力者。
・対象:統計・情報・計算機科学・データサイエンス・経済・経営・金融(FinTech)などを専攻する学部学生,ビジネススクールの学生,若手研究者,実務者,ビックデータの解析を期待される担当者
ビッグデータに活用できる統計的学習を,専門外にもわかりやすくRで実践。〔内容〕導入/統計的学習/線形回帰/分類/リサンプリング法/線形モデル選択と正則化/線形を超えて/木に基づく方法/サポートベクターマシン/教師なし学習
↓全て表示↑少なく表示
内容サンプル


目次
1. 導入
2. 統計的学習
3. 線形回帰
4. 分類
5. リサンプリング法
6. 線形モデル選択と正則化
7. 線形を超えて
8. 木に基づく方法
9. サポートベクターマシン
10. 教師なし学習
2. 統計的学習
3. 線形回帰
4. 分類
5. リサンプリング法
6. 線形モデル選択と正則化
7. 線形を超えて
8. 木に基づく方法
9. サポートベクターマシン
10. 教師なし学習
Users Voice
内容サンプル


著者略歴
Rによるセイバーメトリクス入門

(概要)
セイバーメトリクスとは、ベースボールのデータを利用して戦術を分析することです。本書は、データアナリスト、野球愛好家にRを利用したセイバーメトリクスを紹介します。Rは、データの読み込み、適切なフォーマットへの変換、グラフによるデータの視覚化、統計分析の実行まで、すべての分析ステップを完結できる便利なソフトウェアです(使用されているすべてのデータセットとRコードはオンラインから利用できます)。
第2版では、Rのモダンなデータ分析を可能にするtidyverseを採用し、選手やボールの動きを高速・高精度に分析するために必須となったStatcastによるプレーヤ追跡データを加筆しました。初版のすべてのコードをtidyverseに準拠して修正しました。さまざまなベースボールのプレーとそのデータを通して、モダンなRの利用方法とセイバーメトリクスについて学習できます。
(こんな方におすすめ)
・セイバーメトリクスに興味のある方 ・データアナリスト
(目次)
第1章 野球データセット
1.1 イントロダクション
1.2 Lahman データベース:シーズンごとのデータ
1.3 Game-by-Game(試合ごとのデータ)
1.4 Play-by-Play(打席ごとのデータ)
1.5 投球ごとのデータ
1.6 プレイヤーの動きと打球のデータ
1.7 まとめ
1.8 参考文献
1.9 演習
第2章 R入門
2.1 イントロダクション
2.2 RとRStudioのインストール
2.3 Tidyverse
2.4 データフレーム
2.5 データフレームの操作
2.6 ベクトル
2.7 Rにおけるオブジェクトとコンテナ
2.8 まとまったRコマンド
2.9 データの読み込みと書き込み
2.10 パッケージ
2.11 データの分割、適用、結合
2.12 ヘルプの活用
2.13 参考文献
2.14 演習
第3章 グラフィックス
3.1 イントロダクション
3.2 Character 変数
3.3 グラフの保存
3.4 Numeric 変数:一次元の散布図とヒストグラム
3.5 2つのNumeric変数
3.6 Numeric変数とFactor変数
3.7 Ruth、Aaron、Bonds、A-Rodの比較
3.8 1998年のホームラン王争い
3.9 参考文献
3.10 演習
第4章 得点と勝利の関係
4.1 イントロダクション
4.2 Lahman DatabaseにおけるTeamsテーブル
4.3 線形回帰
4.4 ピタゴラス勝率
4.5 1勝に必要な得点数
4.6 参考文献
4.7 演習
第5章 得点期待値を用いたプレーの価値
5.1 得点期待値行列
5.2 イニングの残りで記録された得点
5.3 行列の作成
5.4 打撃プレーの価値の把握
5.5 Jośe Altuve
5.6 全バッターの打撃機会とパフォーマンス
5.7 打順
5.8 ヒットの種類による得点価値の違い
5.9 盗塁の価値
5.10 参考文献とソフトウェア
5.11 演習
第6章 ボール球とストライク球の効果
6.1 イントロダクション
6.2 バッターのカウントとピッチャーのカウント
6.3 カウントによる行動
6.4 参考文献
6.5 演習
第7章 フレーミング
7.1 イントロダクション
7.2 投球の詳細データ(pitch-level)の取得
7.3 ストライクゾーンはどこか
7.4 ストライク判定確率をモデリング
7.5 フレーミングのモデリング
7.6 参考文献
7.7 演習
第8章 選手の成績推移
8.1 イントロダクション
8.2 Mickey Mantle の打撃成績推移
8.3 成績推移の比較
8.4 ピーク時の年齢の一般的なパターン
8.5 成績推移とポジション
8.6 参考文献
8.7 演習
第9章 シミュレーション
9.1 イントロダクション
9.2 イニング途中のシミュレーション
9.3 シーズンのシミュレーション
9.4 参考文献
9.5 演習
第10章 バッターの好不調分析
10.1 イントロダクション
10.2 好調
10.3 各選手の打数レベルでの連続安打
10.4 Statcastにおける打球速度の特有パターン
10.5 参考文献
10.6 演習
第11章 データベースを利用したパークファクターの計算
11.1 イントロダクション
11.2 MySQL のインストールとデータベースの作成
11.3 R からMySQL への接続
11.4 R からMySQL のGame log データベースへの入力
11.5 Rからクエリを実行する
11.6 独自の野球データベースの構築
11.7 基本的なパークファクターの計算
11.8 参考文献
11.9 演習
第12章 Statcastの打球データ
12.1 イントロダクション
12.2 スプレーチャート
12.3 打球角度と打球速度
12.4 ホームラン確率のモデリング
12.5 打球角度は能力なのか
12.7 演習
付録A Retrosheetファイルの説明
A.1 打席ごとのデータファイルのダウンロード
A.2 event file:簡潔なリファレンス
A.3 ピッチシークエンスのパース
付録B MLBAM Gameday・PITCHf/xデータの活用
B.1 イントロダクション
B.2 データが保存されている場所
B.3 PITCHf/xデータを用いた分析
B.4 データの詳細
B.5 Gameday and PITCHf/xデータに関するメモ
B.6 雑集
付録C Statcastデータの活用
C.1 イントロダクション
C.2 試合のシチュエーション変数
C.3 投球に関する変数
C.4 プレーのイベント変数
C.5 打球に関する変数
C.6 導出される変数
C.7 守備変数
セイバーメトリクスとは、ベースボールのデータを利用して戦術を分析することです。本書は、データアナリスト、野球愛好家にRを利用したセイバーメトリクスを紹介します。Rは、データの読み込み、適切なフォーマットへの変換、グラフによるデータの視覚化、統計分析の実行まで、すべての分析ステップを完結できる便利なソフトウェアです(使用されているすべてのデータセットとRコードはオンラインから利用できます)。
第2版では、Rのモダンなデータ分析を可能にするtidyverseを採用し、選手やボールの動きを高速・高精度に分析するために必須となったStatcastによるプレーヤ追跡データを加筆しました。初版のすべてのコードをtidyverseに準拠して修正しました。さまざまなベースボールのプレーとそのデータを通して、モダンなRの利用方法とセイバーメトリクスについて学習できます。
(こんな方におすすめ)
・セイバーメトリクスに興味のある方 ・データアナリスト
(目次)
第1章 野球データセット
1.1 イントロダクション
1.2 Lahman データベース:シーズンごとのデータ
1.3 Game-by-Game(試合ごとのデータ)
1.4 Play-by-Play(打席ごとのデータ)
1.5 投球ごとのデータ
1.6 プレイヤーの動きと打球のデータ
1.7 まとめ
1.8 参考文献
1.9 演習
第2章 R入門
2.1 イントロダクション
2.2 RとRStudioのインストール
2.3 Tidyverse
2.4 データフレーム
2.5 データフレームの操作
2.6 ベクトル
2.7 Rにおけるオブジェクトとコンテナ
2.8 まとまったRコマンド
2.9 データの読み込みと書き込み
2.10 パッケージ
2.11 データの分割、適用、結合
2.12 ヘルプの活用
2.13 参考文献
2.14 演習
第3章 グラフィックス
3.1 イントロダクション
3.2 Character 変数
3.3 グラフの保存
3.4 Numeric 変数:一次元の散布図とヒストグラム
3.5 2つのNumeric変数
3.6 Numeric変数とFactor変数
3.7 Ruth、Aaron、Bonds、A-Rodの比較
3.8 1998年のホームラン王争い
3.9 参考文献
3.10 演習
第4章 得点と勝利の関係
4.1 イントロダクション
4.2 Lahman DatabaseにおけるTeamsテーブル
4.3 線形回帰
4.4 ピタゴラス勝率
4.5 1勝に必要な得点数
4.6 参考文献
4.7 演習
第5章 得点期待値を用いたプレーの価値
5.1 得点期待値行列
5.2 イニングの残りで記録された得点
5.3 行列の作成
5.4 打撃プレーの価値の把握
5.5 Jośe Altuve
5.6 全バッターの打撃機会とパフォーマンス
5.7 打順
5.8 ヒットの種類による得点価値の違い
5.9 盗塁の価値
5.10 参考文献とソフトウェア
5.11 演習
第6章 ボール球とストライク球の効果
6.1 イントロダクション
6.2 バッターのカウントとピッチャーのカウント
6.3 カウントによる行動
6.4 参考文献
6.5 演習
第7章 フレーミング
7.1 イントロダクション
7.2 投球の詳細データ(pitch-level)の取得
7.3 ストライクゾーンはどこか
7.4 ストライク判定確率をモデリング
7.5 フレーミングのモデリング
7.6 参考文献
7.7 演習
第8章 選手の成績推移
8.1 イントロダクション
8.2 Mickey Mantle の打撃成績推移
8.3 成績推移の比較
8.4 ピーク時の年齢の一般的なパターン
8.5 成績推移とポジション
8.6 参考文献
8.7 演習
第9章 シミュレーション
9.1 イントロダクション
9.2 イニング途中のシミュレーション
9.3 シーズンのシミュレーション
9.4 参考文献
9.5 演習
第10章 バッターの好不調分析
10.1 イントロダクション
10.2 好調
10.3 各選手の打数レベルでの連続安打
10.4 Statcastにおける打球速度の特有パターン
10.5 参考文献
10.6 演習
第11章 データベースを利用したパークファクターの計算
11.1 イントロダクション
11.2 MySQL のインストールとデータベースの作成
11.3 R からMySQL への接続
11.4 R からMySQL のGame log データベースへの入力
11.5 Rからクエリを実行する
11.6 独自の野球データベースの構築
11.7 基本的なパークファクターの計算
11.8 参考文献
11.9 演習
第12章 Statcastの打球データ
12.1 イントロダクション
12.2 スプレーチャート
12.3 打球角度と打球速度
12.4 ホームラン確率のモデリング
12.5 打球角度は能力なのか
12.7 演習
付録A Retrosheetファイルの説明
A.1 打席ごとのデータファイルのダウンロード
A.2 event file:簡潔なリファレンス
A.3 ピッチシークエンスのパース
付録B MLBAM Gameday・PITCHf/xデータの活用
B.1 イントロダクション
B.2 データが保存されている場所
B.3 PITCHf/xデータを用いた分析
B.4 データの詳細
B.5 Gameday and PITCHf/xデータに関するメモ
B.6 雑集
付録C Statcastデータの活用
C.1 イントロダクション
C.2 試合のシチュエーション変数
C.3 投球に関する変数
C.4 プレーのイベント変数
C.5 打球に関する変数
C.6 導出される変数
C.7 守備変数
↓全て表示↑少なく表示
内容サンプル


目次
■第1章 野球データセット
1.1 イントロダクション
1.2 Lahman データベース:シーズンごとのデータ
1.2.1 スラッガーたちのホームラン数の推移
1.2.2 データの取得
1.2.3 Master テーブル
1.2.4 Batting テーブル
1.2.5 Pitching テーブル
1.2.6 Fielding テーブル
1.2.7 Teams テーブル
1.2.8 クイズ
1.3 Game-by-Game(試合ごとのデータ)
1.3.1 1998 年のMcGwireとSosaのホームラン王争い
1.3.2 Retrosheet
1.3.3 Game Logs
1.3.4 RetrosheetからGame logを取得
1.3.5 Game logの例
1.3.6 クイズ
1.4 Play-by-Play(打席ごとのデータ)
1.4.1 Event files
1.4.2 イベントの例
1.4.3 クイズ
1.5 投球ごとのデータ
1.5.1 MLBAM GamedayとPITCHf/x
1.5.2 PITCHf/xの例
1.5.3 クイズ
1.6 プレイヤーの動きと打球のデータ
1.6.1 Statcast
1.6.2 Baseball Savant data
1.6.3 クイズ
1.7 まとめ
1.8 参考文献
1.9 演習
■第2章 R入門
2.1 イントロダクション
2.2 RとRStudioのインストール
2.3 Tidyverse
2.3.1 dplyr
2.3.2 Pipe
2.3.3 ggplot2
2.3.4 他のパッケージ
2.4 データフレーム
2.4.1 Warren Spahn のキャリア
2.4.2 データフレーム
2.5 データフレームの操作
2.5.1 データフレームの結合・抽出
2.6 ベクトル
2.6.1 ベクトルの定義・計算
2.6.2 ベクトルに関する関数群
2.6.3 ベクトルインデックスと論理変数
2.7 Rにおけるオブジェクトとコンテナ
2.7.1 Characterデータとデータフレーム
2.7.2 Factors
2.7.3 Lists
2.8 まとまったRコマンド
2.8.1 Rのスクリプト
2.8.2 Rの関数
2.9 データの読み込みと書き込み
2.9.1 ファイルから読み込む
2.9.2 データセットの保存
2.10 パッケージ
2.11 データの分割、適用、結合2.11.1 map 関数を使った繰り返し処理
2.11.2 他の例
2.12 ヘルプの活用
2.13 参考文献
2.14 演習
■第3章 グラフィックス
3.1 イントロダクション
3.2 Character 変数
3.2.1 棒グラフ
3.2.2 軸のラベルとタイトルを追加する
3.2.3 Character 変数を使った他の種類のグラフ
3.3 グラフの保存
3.4 Numeric 変数:一次元の散布図とヒストグラム
3.5 2つのNumeric変数
3.5.1 散布図
3.5.2 グラフの作成
3.6 Numeric変数とFactor変数
3.6.1 並列一次元散布図
3.6.2 並列箱ひげ図
3.7 Ruth、Aaron、Bonds、A-Rodの比較
3.7.1 データの取得
3.7.2 プレイヤーのデータフレームの作成
3.7.3 グラフの作成
3.8 1998年のホームラン王争い
3.8.1 データの取得
3.8.2 変数の抽出
3.8.3 グラフの作成
3.9 参考文献
3.10 演習
■第4章 得点と勝利の関係
4.1 イントロダクション
4.2 Lahman DatabaseにおけるTeamsテーブル
4.3 線形回帰
4.4 ピタゴラス勝率
4.4.1 ピタゴラスモデルの指数
4.4.2 ピタゴラスモデルの良い予測と悪い予測
4.5 1勝に必要な得点数
4.6 参考文献
4.7 演習
■第5章 得点期待値を用いたプレーの価値
5.1 得点期待値行列
5.2 イニングの残りで記録された得点
5.3 行列の作成
5.4 打撃プレーの価値の把握
5.5 Jose Altuve
5.6 全バッターの打撃機会とパフォーマンス
5.7 打順
5.8 ヒットの種類による得点価値の違い
5.8.1 ホームランの価値
5.8.2 シングルヒットの価値
5.9 盗塁の価値
5.10 参考文献とソフトウェア
5.11 演習
■第6章 ボール球とストライク球の効果
6.1 イントロダクション
6.2 バッターのカウントとピッチャーのカウント
6.2.1 あるピッチャーの例
6.2.2 Retrosheet からピッチシークエンスを検討する
6.2.3 カウントごとの予測される得点価値
6.2.4 打席における「経過したカウント」の重要性
6.3 カウントによる行動
6.3.1 カウントによるスイングの傾向
6.3.2 ボール/ストライクカウントの影響
6.3.3 カウントによる投球の選択8
6.3.4 カウントによる球審の行動
6.4 参考文献
6.5 演習
■第7章 フレーミング
7.1 イントロダクション
7.2 投球の詳細データ(pitch-level)の取得
7.3 ストライクゾーンはどこか
7.4 ストライク判定確率をモデリング
7.4.1 推定結果の可視化
7.4.2 推定した平面の可視化
7.4.3 利き腕の調整
7.5 フレーミングのモデリング
7.6 参考文献
7.7 演習
■第8章 選手の成績推移
8.1 イントロダクション
8.2 Mickey Mantle の打撃成績推移
8.3 成績推移の比較
8.3.1 事前準備
8.3.2 通算成績のを計算
8.3.3 類似性スコアの計算
8.3.4 年齢、OBP(出塁率)、SLG(長打率)、OPS の定義
8.3.5 成績推移に対するフィッティングとプロット
8.4 ピーク時の年齢の一般的なパターン
8.4.1 全選手に対する成績推移の推定
8.4.2 ピーク時の年齢の変化
8.4.3 ピーク時の年齢と通算打数
8.5 成績推移とポジション
8.6 参考文献
8.7 演習
■第9章 シミュレーション
9.1 イントロダクション
9.2 イニング途中のシミュレーション
9.2.1 マルコフ連鎖
9.2.2 得点期待値を使った評価
9.2.3 遷移確率の計算
9.2.4 マルコフ連鎖によるシミュレーション
9.2.5 得点期待値のその先
9.2.6 チームごとの遷移確率
9.3 シーズンのシミュレーション
9.3.1 Bradley-Terry モデル
9.3.2 スケジュールを組み立てる
9.3.3 素質のシミュレーションと勝率の計算
9.3.4 レギュラーシーズンのシミュレーション
9.3.5 ポストシーズンのシミュレーション
9.3.6 1シーズンをシミュレーションする関数
9.3.7 たくさんのシーズンをシミュレーションする
9.4 参考文献
9.5 演習
■第10章 バッターの好不調分析
10.1 イントロダクション
10.2 好調
10.2.1 連続試合安打を見つける
10.2.2 移動平均を考慮した打率
10.3 各選手の打数レベルでの連続安打
10.3.1 安打とアウトの連続
10.3.2 移動平均打率
10.3.3 全選手のスランプを見つける
10.3.4 イチローとMike Troutの連続安打は異常か?
10.4 Statcastにおける打球速度の特有パターン
10.5 参考文献
10.6 演習
■第11章 データベースを利用したパークファクターの計算
11.1 イントロダクション
11.2 MySQL のインストールとデータベースの作成
11.3 R からMySQL への接続
11.3.1 RMySQL を使った接続
11.3.2 R から他のデータベースへの接続
11.4 R からMySQL のGame log データベースへの入力
11.4.1 Retrosheet からR へ
11.4.2 R からMySQL へ
11.5 Rからクエリを実行する
11.5.1 イントロダクション
11.5.2 Coors Fieldと得点の関係
11.6 独自の野球データベースの構築
11.6.1 Lahmanのデータベース
11.6.2 Retrosheetのデータベース
11.6.3 PITCHf/xのデータベース
11.6.4 Statcastのデータベース
11.7 基本的なパークファクターの計算
11.7.1 Rにデータを読み込む
11.7.2 ホームランに与えるパークファクターの影響
11.7.3 提案アプローチの仮定
11.7.4 パークファクターの適用
11.8 参考文献
11.9 演習
■第12章 Statcastの打球データ
12.1 イントロダクション
12.2 スプレーチャート
12.2.1 1年分のStatcastデータの取得
12.2.2 打球方向の傾向と内野守備
12.3 打球角度と打球速度
12.3.1 打球角度vs打球速度の散布図
12.4 ホームラン確率のモデリング
12.4.1 一般化加法モデル(GAM)
12.4.2 滑らかな予測
12.4.3 2017シーズンのホームランを推定
12.5 打球角度は能力なのか
12.5.1 打球角度の分布
12.5.2 シーズン前半の打球角度とシーズン後半の打球角度の相関
12.7 演習
■付録A Retrosheetファイルの説明
A.1 打席ごとのデータファイルのダウンロード
A.1.1 イントロダクション
A.1.2 セットアップ
A.1.3 特定シーズンへの関数の使用
A.1.4 ファイルの読み込み
A.1.5 parse retrosheet pbp関数
A.2 event file:簡潔なリファレンス
A.2.1 試合とイベントの識別子
A.2.2 試合の状態
A.3 ピッチシークエンスのパース
A.3.1 イントロダクション
A.3.2 セットアップ
A.3.3 全カウントの評価
■付録B MLBAM Gameday・PITCHf/xデータの活用
B.1 イントロダクション
B.2 データが保存されている場所
B.3 PITCHf/xデータを用いた分析
B.3.1 オンラインリソースからデータを取得
B.3.2 Rによる解析
B.3.3 XMLの展開
B.3.4 pitchRx:PITCHf/xデータのためのR関数
B.4 データの詳細
B.4.1 atbatに関する要素
B.4.2 pitchに関する要素
B.4.3 hipに関する要素(打球位置のデータ)
B.5 Gameday and PITCHf/xデータに関するメモ
B.6 雑集
B.6.1 投球の軌道を計算
B.6.2 他のデータソースとのクロスリファレンス
B.6.3 オンラインリソース
■付録C Statcastデータの活用
C.1 イントロダクション
C.2 試合のシチュエーション変数
C.3 投球に関する変数
C.4 プレーのイベント変数
C.5 打球に関する変数
C.6 導出される変数
C.7 守備変数
参考文献
1.1 イントロダクション
1.2 Lahman データベース:シーズンごとのデータ
1.2.1 スラッガーたちのホームラン数の推移
1.2.2 データの取得
1.2.3 Master テーブル
1.2.4 Batting テーブル
1.2.5 Pitching テーブル
1.2.6 Fielding テーブル
1.2.7 Teams テーブル
1.2.8 クイズ
1.3 Game-by-Game(試合ごとのデータ)
1.3.1 1998 年のMcGwireとSosaのホームラン王争い
1.3.2 Retrosheet
1.3.3 Game Logs
1.3.4 RetrosheetからGame logを取得
1.3.5 Game logの例
1.3.6 クイズ
1.4 Play-by-Play(打席ごとのデータ)
1.4.1 Event files
1.4.2 イベントの例
1.4.3 クイズ
1.5 投球ごとのデータ
1.5.1 MLBAM GamedayとPITCHf/x
1.5.2 PITCHf/xの例
1.5.3 クイズ
1.6 プレイヤーの動きと打球のデータ
1.6.1 Statcast
1.6.2 Baseball Savant data
1.6.3 クイズ
1.7 まとめ
1.8 参考文献
1.9 演習
■第2章 R入門
2.1 イントロダクション
2.2 RとRStudioのインストール
2.3 Tidyverse
2.3.1 dplyr
2.3.2 Pipe
2.3.3 ggplot2
2.3.4 他のパッケージ
2.4 データフレーム
2.4.1 Warren Spahn のキャリア
2.4.2 データフレーム
2.5 データフレームの操作
2.5.1 データフレームの結合・抽出
2.6 ベクトル
2.6.1 ベクトルの定義・計算
2.6.2 ベクトルに関する関数群
2.6.3 ベクトルインデックスと論理変数
2.7 Rにおけるオブジェクトとコンテナ
2.7.1 Characterデータとデータフレーム
2.7.2 Factors
2.7.3 Lists
2.8 まとまったRコマンド
2.8.1 Rのスクリプト
2.8.2 Rの関数
2.9 データの読み込みと書き込み
2.9.1 ファイルから読み込む
2.9.2 データセットの保存
2.10 パッケージ
2.11 データの分割、適用、結合2.11.1 map 関数を使った繰り返し処理
2.11.2 他の例
2.12 ヘルプの活用
2.13 参考文献
2.14 演習
■第3章 グラフィックス
3.1 イントロダクション
3.2 Character 変数
3.2.1 棒グラフ
3.2.2 軸のラベルとタイトルを追加する
3.2.3 Character 変数を使った他の種類のグラフ
3.3 グラフの保存
3.4 Numeric 変数:一次元の散布図とヒストグラム
3.5 2つのNumeric変数
3.5.1 散布図
3.5.2 グラフの作成
3.6 Numeric変数とFactor変数
3.6.1 並列一次元散布図
3.6.2 並列箱ひげ図
3.7 Ruth、Aaron、Bonds、A-Rodの比較
3.7.1 データの取得
3.7.2 プレイヤーのデータフレームの作成
3.7.3 グラフの作成
3.8 1998年のホームラン王争い
3.8.1 データの取得
3.8.2 変数の抽出
3.8.3 グラフの作成
3.9 参考文献
3.10 演習
■第4章 得点と勝利の関係
4.1 イントロダクション
4.2 Lahman DatabaseにおけるTeamsテーブル
4.3 線形回帰
4.4 ピタゴラス勝率
4.4.1 ピタゴラスモデルの指数
4.4.2 ピタゴラスモデルの良い予測と悪い予測
4.5 1勝に必要な得点数
4.6 参考文献
4.7 演習
■第5章 得点期待値を用いたプレーの価値
5.1 得点期待値行列
5.2 イニングの残りで記録された得点
5.3 行列の作成
5.4 打撃プレーの価値の把握
5.5 Jose Altuve
5.6 全バッターの打撃機会とパフォーマンス
5.7 打順
5.8 ヒットの種類による得点価値の違い
5.8.1 ホームランの価値
5.8.2 シングルヒットの価値
5.9 盗塁の価値
5.10 参考文献とソフトウェア
5.11 演習
■第6章 ボール球とストライク球の効果
6.1 イントロダクション
6.2 バッターのカウントとピッチャーのカウント
6.2.1 あるピッチャーの例
6.2.2 Retrosheet からピッチシークエンスを検討する
6.2.3 カウントごとの予測される得点価値
6.2.4 打席における「経過したカウント」の重要性
6.3 カウントによる行動
6.3.1 カウントによるスイングの傾向
6.3.2 ボール/ストライクカウントの影響
6.3.3 カウントによる投球の選択8
6.3.4 カウントによる球審の行動
6.4 参考文献
6.5 演習
■第7章 フレーミング
7.1 イントロダクション
7.2 投球の詳細データ(pitch-level)の取得
7.3 ストライクゾーンはどこか
7.4 ストライク判定確率をモデリング
7.4.1 推定結果の可視化
7.4.2 推定した平面の可視化
7.4.3 利き腕の調整
7.5 フレーミングのモデリング
7.6 参考文献
7.7 演習
■第8章 選手の成績推移
8.1 イントロダクション
8.2 Mickey Mantle の打撃成績推移
8.3 成績推移の比較
8.3.1 事前準備
8.3.2 通算成績のを計算
8.3.3 類似性スコアの計算
8.3.4 年齢、OBP(出塁率)、SLG(長打率)、OPS の定義
8.3.5 成績推移に対するフィッティングとプロット
8.4 ピーク時の年齢の一般的なパターン
8.4.1 全選手に対する成績推移の推定
8.4.2 ピーク時の年齢の変化
8.4.3 ピーク時の年齢と通算打数
8.5 成績推移とポジション
8.6 参考文献
8.7 演習
■第9章 シミュレーション
9.1 イントロダクション
9.2 イニング途中のシミュレーション
9.2.1 マルコフ連鎖
9.2.2 得点期待値を使った評価
9.2.3 遷移確率の計算
9.2.4 マルコフ連鎖によるシミュレーション
9.2.5 得点期待値のその先
9.2.6 チームごとの遷移確率
9.3 シーズンのシミュレーション
9.3.1 Bradley-Terry モデル
9.3.2 スケジュールを組み立てる
9.3.3 素質のシミュレーションと勝率の計算
9.3.4 レギュラーシーズンのシミュレーション
9.3.5 ポストシーズンのシミュレーション
9.3.6 1シーズンをシミュレーションする関数
9.3.7 たくさんのシーズンをシミュレーションする
9.4 参考文献
9.5 演習
■第10章 バッターの好不調分析
10.1 イントロダクション
10.2 好調
10.2.1 連続試合安打を見つける
10.2.2 移動平均を考慮した打率
10.3 各選手の打数レベルでの連続安打
10.3.1 安打とアウトの連続
10.3.2 移動平均打率
10.3.3 全選手のスランプを見つける
10.3.4 イチローとMike Troutの連続安打は異常か?
10.4 Statcastにおける打球速度の特有パターン
10.5 参考文献
10.6 演習
■第11章 データベースを利用したパークファクターの計算
11.1 イントロダクション
11.2 MySQL のインストールとデータベースの作成
11.3 R からMySQL への接続
11.3.1 RMySQL を使った接続
11.3.2 R から他のデータベースへの接続
11.4 R からMySQL のGame log データベースへの入力
11.4.1 Retrosheet からR へ
11.4.2 R からMySQL へ
11.5 Rからクエリを実行する
11.5.1 イントロダクション
11.5.2 Coors Fieldと得点の関係
11.6 独自の野球データベースの構築
11.6.1 Lahmanのデータベース
11.6.2 Retrosheetのデータベース
11.6.3 PITCHf/xのデータベース
11.6.4 Statcastのデータベース
11.7 基本的なパークファクターの計算
11.7.1 Rにデータを読み込む
11.7.2 ホームランに与えるパークファクターの影響
11.7.3 提案アプローチの仮定
11.7.4 パークファクターの適用
11.8 参考文献
11.9 演習
■第12章 Statcastの打球データ
12.1 イントロダクション
12.2 スプレーチャート
12.2.1 1年分のStatcastデータの取得
12.2.2 打球方向の傾向と内野守備
12.3 打球角度と打球速度
12.3.1 打球角度vs打球速度の散布図
12.4 ホームラン確率のモデリング
12.4.1 一般化加法モデル(GAM)
12.4.2 滑らかな予測
12.4.3 2017シーズンのホームランを推定
12.5 打球角度は能力なのか
12.5.1 打球角度の分布
12.5.2 シーズン前半の打球角度とシーズン後半の打球角度の相関
12.7 演習
■付録A Retrosheetファイルの説明
A.1 打席ごとのデータファイルのダウンロード
A.1.1 イントロダクション
A.1.2 セットアップ
A.1.3 特定シーズンへの関数の使用
A.1.4 ファイルの読み込み
A.1.5 parse retrosheet pbp関数
A.2 event file:簡潔なリファレンス
A.2.1 試合とイベントの識別子
A.2.2 試合の状態
A.3 ピッチシークエンスのパース
A.3.1 イントロダクション
A.3.2 セットアップ
A.3.3 全カウントの評価
■付録B MLBAM Gameday・PITCHf/xデータの活用
B.1 イントロダクション
B.2 データが保存されている場所
B.3 PITCHf/xデータを用いた分析
B.3.1 オンラインリソースからデータを取得
B.3.2 Rによる解析
B.3.3 XMLの展開
B.3.4 pitchRx:PITCHf/xデータのためのR関数
B.4 データの詳細
B.4.1 atbatに関する要素
B.4.2 pitchに関する要素
B.4.3 hipに関する要素(打球位置のデータ)
B.5 Gameday and PITCHf/xデータに関するメモ
B.6 雑集
B.6.1 投球の軌道を計算
B.6.2 他のデータソースとのクロスリファレンス
B.6.3 オンラインリソース
■付録C Statcastデータの活用
C.1 イントロダクション
C.2 試合のシチュエーション変数
C.3 投球に関する変数
C.4 プレーのイベント変数
C.5 打球に関する変数
C.6 導出される変数
C.7 守備変数
参考文献
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
露崎博之(ツユザキヒロユキ)
2015年に中央大学理工学部経営システム工学科を卒業後、マーケティングリサーチ会社に入社。2020年からはプロ野球球団にて編成・スカウティング担当のアナリストとして従事。スポーツ×アナリティクスの更なる飛躍に向けてイベントの主催など鋭意活動している
Yoshihiro Nishiwaki(YOSHIHIRO NISHIWAKI)
London School of Economics and Political Science(LSE)修了。Rは学生時代に独学。1994年生まれ(本データはこの書籍が刊行された当時に掲載されていたものです)
2015年に中央大学理工学部経営システム工学科を卒業後、マーケティングリサーチ会社に入社。2020年からはプロ野球球団にて編成・スカウティング担当のアナリストとして従事。スポーツ×アナリティクスの更なる飛躍に向けてイベントの主催など鋭意活動している
Yoshihiro Nishiwaki(YOSHIHIRO NISHIWAKI)
London School of Economics and Political Science(LSE)修了。Rは学生時代に独学。1994年生まれ(本データはこの書籍が刊行された当時に掲載されていたものです)
↓全て表示↑少なく表示
Rによるスクレイピング入門

本書では、統計解析ツール「R」を使って、膨大なウェブサイトから情報収集を行う方法(スクレイピングの手法)をわかりやすく解説しています。
HTMLやXMLの解析、APIを活用したデータ収集、データを取得した後の整形など、実践を交えながら、そのテクニックを紹介しています。
HTMLやXMLの解析、APIを活用したデータ収集、データを取得した後の整形など、実践を交えながら、そのテクニックを紹介しています。
目次
01 ウェブスクレイピングの準備
02 ウェブ技術入門
03 ウェブスクレイピング・API入門
04 ウェブスクレイピング実践
05 API実践
06 オープンデータの活用
02 ウェブ技術入門
03 ウェブスクレイピング・API入門
04 ウェブスクレイピング実践
05 API実践
06 オープンデータの活用
Users Voice
著者略歴
石田基広(イシダモトヒロ)
徳島大学大学院教授。大学ではプログラミング、データ分析、テキスト分析などの科目を担当している
市川太祐(イチカワダイスケ)
医師。サスメド株式会社にて、スマートフォンアプリを用いた不眠症治療に従事している。「医療の現場でアプリが処方される未来」の実現に向けて、学問としての「デジタル医療」の確立を目指す
瓜生真也(ウリュウシンヤ)
エンジニア。株式会社ナイトレイにて、位置情報データを用いた分析、Shinyによるアプリケーション開発を担当。KPI設定や分析基盤構築にも取り組む
湯谷啓明(ユタニヒロアキ)
インフラエンジニア。サイボウズ株式会社のSREチームに所属。グラフを描くツールを探していてggplot2と出会い、Rに興味を持つ(本データはこの書籍が刊行された当時に掲載されていたものです)
徳島大学大学院教授。大学ではプログラミング、データ分析、テキスト分析などの科目を担当している
市川太祐(イチカワダイスケ)
医師。サスメド株式会社にて、スマートフォンアプリを用いた不眠症治療に従事している。「医療の現場でアプリが処方される未来」の実現に向けて、学問としての「デジタル医療」の確立を目指す
瓜生真也(ウリュウシンヤ)
エンジニア。株式会社ナイトレイにて、位置情報データを用いた分析、Shinyによるアプリケーション開発を担当。KPI設定や分析基盤構築にも取り組む
湯谷啓明(ユタニヒロアキ)
インフラエンジニア。サイボウズ株式会社のSREチームに所属。グラフを描くツールを探していてggplot2と出会い、Rに興味を持つ(本データはこの書籍が刊行された当時に掲載されていたものです)
↓全て表示↑少なく表示
サラっとできる!フリー統計ソフトEZR(Easy R)でカンタン統計解析

統計解析の定番ソフト「R」が、EZR(Easy R)で手軽に使いこなせる!
本書は、統計解析の定番ソフト「R」がGUIで使いこなせる「EZR(Easy R)」を活用して、初心者でも手軽に統計解析ができる方法を解説する入門書です。
EZRを使えば、コンソール入力を行わなくても、マウスでサクサク解析を進めることができます。しかも、EZRの開発者である著者が専門とする医療分野を中心に、統計解析の現場で活用されている本格的なパッケージなので、安心して使うことができます。
本書では、多くの方に親しみやすいテーマを扱いながら、日常生活から実務まで役立つ統計解析の基本的な考え方をやさしく解説するとともに、サンプルデータを用いたわかりやすい事例をとおして、EZRを操作しながら統計解析手法の基本を押さえることができます。
EZRと本書で、サラっとカンタンに、統計解析を始めましょう!
本書は、統計解析の定番ソフト「R」がGUIで使いこなせる「EZR(Easy R)」を活用して、初心者でも手軽に統計解析ができる方法を解説する入門書です。
EZRを使えば、コンソール入力を行わなくても、マウスでサクサク解析を進めることができます。しかも、EZRの開発者である著者が専門とする医療分野を中心に、統計解析の現場で活用されている本格的なパッケージなので、安心して使うことができます。
本書では、多くの方に親しみやすいテーマを扱いながら、日常生活から実務まで役立つ統計解析の基本的な考え方をやさしく解説するとともに、サンプルデータを用いたわかりやすい事例をとおして、EZRを操作しながら統計解析手法の基本を押さえることができます。
EZRと本書で、サラっとカンタンに、統計解析を始めましょう!
内容サンプル


目次
プロローグ 雨の文化祭と統計学
第1章 結婚するならスポーツ選手?-平均値と中央値
第2章 テストの偏差値で一喜一憂ー分散・標準偏差
第3章 引越し先の家賃は高い?-t検定、相関、回帰分析
第4章 新製品でアンケート調査ー比率の検定と多変量解析
第5章 SNS?友人の紹介?長続きするのはどんなカップル?-生存解析
付録
第1章 結婚するならスポーツ選手?-平均値と中央値
第2章 テストの偏差値で一喜一憂ー分散・標準偏差
第3章 引越し先の家賃は高い?-t検定、相関、回帰分析
第4章 新製品でアンケート調査ー比率の検定と多変量解析
第5章 SNS?友人の紹介?長続きするのはどんなカップル?-生存解析
付録
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
神田善伸(カンダヨシノブ)
1991年東京大学医学部医学科卒業、東京大学医学部附属病院内科研修医。1992年JR東京総合病院内科研修医。1994年都立駒込病院血液内科医員。1997年東京大学大学院医学系研究科修了、東京大学医学部附属病院無菌治療部医員。1998年国立国際医療センター血液内科医員。2000年国立がんセンター中央病院幹細胞移植療法室医員。2001年東京大学医学部附属病院無菌治療部助手。2005年東京大学医学部附属病院血液・腫瘍内科講師。2007年自治医科大学総合医学第一講座・同附属さいたま医療センター血液科教授(現職)。2014年自治医科大学内科学講座血液学部門教授(現職・兼任)、自治医科大学臨床研究支援センター長(本データはこの書籍が刊行された当時に掲載されていたものです)
1991年東京大学医学部医学科卒業、東京大学医学部附属病院内科研修医。1992年JR東京総合病院内科研修医。1994年都立駒込病院血液内科医員。1997年東京大学大学院医学系研究科修了、東京大学医学部附属病院無菌治療部医員。1998年国立国際医療センター血液内科医員。2000年国立がんセンター中央病院幹細胞移植療法室医員。2001年東京大学医学部附属病院無菌治療部助手。2005年東京大学医学部附属病院血液・腫瘍内科講師。2007年自治医科大学総合医学第一講座・同附属さいたま医療センター血液科教授(現職)。2014年自治医科大学内科学講座血液学部門教授(現職・兼任)、自治医科大学臨床研究支援センター長(本データはこの書籍が刊行された当時に掲載されていたものです)
↓全て表示↑少なく表示
実践 Rによるテキストマイニング:センチメント分析・単語分散表現・機械学習・Pythonラッパー

今やテキストマイニングは、文章を単語に切り分けて、単語の出現頻度を数えるだけにはとどまりません。
商品やイベントに対するSNS上の意見をポジティブ・ネガティブに分ければ、何が評価されて、どこを改善すべきかが一目瞭然。
政治家の演説のトピックが、時代とともにどう移り変わってきたかを解析すると、社会の変化を見て取ることもできます。 小説の話題展開の流れや、登場人物とキーワードの結びつきも、自動で分析可能です。
文書解析で本当にやりたかったこれらのことは、 Rで手軽に実現できます。
テキストマイニング定番書の著者による、次の一歩のためのやさしい手引きです。
[もっと基本的なことから学びたい方は、同著者による「Rによるテキストマイニング入門[第2版](森北出版)」もご覧ください]
〈本書で扱う主な内容〉
●センチメント分析
日本語極性辞書を用いて、単語の極性からテキスト全体がポジティブかネガティブか判断。
●単語分散表現
単語の頻度だけでなく、出現位置に注目し、単語どうしの意味の関連性を数値化。
●機械学習、ディープラーニング
機械学習を用いて、より高度な解析も実現。Pythonを前提とした訓練済みモデルやディープラーニングのフレームワークも、 RStudioから簡単に利用可能。
◆電子版が発行されました
◆詳細は、森北出版Webサイトにて
【目次】
第1章 Rによる日本語テキスト解析の基礎
1.1 ファイルのダウンロードと読み込み
1.2 日本語形態素解析
1.3 ワードクラウド
1.4 ネットワークグラフ
第2章 センチメント分析
2.1 日本語極性辞書
2.2 テキストを文で区切る
2.3 感情極性値辞書の適用
2.4 感情極性値の時系列
第3章 構造的トピックモデル
3.1 トピックの分析方法
3.2 総理大臣所信表明演説の解析
3.3 ストップワードの削除
3.4 stmパッケージのためのデータ変換
3.5 stmパッケージによるトピック数の推定
3.6 トピックモデルの実行
3.7 夏目漱石『こころ』の解析
3.8 topicmodelsパッケージによるトピックモデル
3.9 ldatuningパッケージによるトピック数の推定
3.10 stm パッケージによるトピックモデル
第4章 Twitter投稿テキストの評価
4.1 API とは
4.2 Twitter APIの利用
4.3 ツイートの取得と前処理
4.4 形態素解析の実行
4.5 ggwordcloudパッケージによるワードクラウドの作図
4.6 ネットワークグラフ
4.7 ツイートの内容判定
4.8 ユーザーのグループ化
4.9 投稿者のプロフィールの極性比較
第5章 機械学習による予測
5.1 Twitter日本語評判分析データセット
5.2 ツイートの収集
5.3 ツイートの内容を予測するモデル
5.4 正則
5.5 glmnetパッケージによる回帰分析
5.6 機械学習の作業ルーティン
5.7 ランダムフォレスト
第6章 単語分散表現
6.1 単語ベクトル
6.2 単語分散表現
第7章 RからPythonライブラリを実行
7.1 訓練済み単語分散表現
7.2 PythonをRから利用するためのreticulate パッケージ
7.3 keras パッケージによるディープラーニング
補 遺
A.1 stringiパッケージ
A.2 udpipeパッケージ
A.3 udpipeによるトピックモデル
A.4 文章の重要度判定
A.5 RMeCabを活用する
A.6 テキストデータ取得に便利なパッケージ
参考文献
索 引
商品やイベントに対するSNS上の意見をポジティブ・ネガティブに分ければ、何が評価されて、どこを改善すべきかが一目瞭然。
政治家の演説のトピックが、時代とともにどう移り変わってきたかを解析すると、社会の変化を見て取ることもできます。 小説の話題展開の流れや、登場人物とキーワードの結びつきも、自動で分析可能です。
文書解析で本当にやりたかったこれらのことは、 Rで手軽に実現できます。
テキストマイニング定番書の著者による、次の一歩のためのやさしい手引きです。
[もっと基本的なことから学びたい方は、同著者による「Rによるテキストマイニング入門[第2版](森北出版)」もご覧ください]
〈本書で扱う主な内容〉
●センチメント分析
日本語極性辞書を用いて、単語の極性からテキスト全体がポジティブかネガティブか判断。
●単語分散表現
単語の頻度だけでなく、出現位置に注目し、単語どうしの意味の関連性を数値化。
●機械学習、ディープラーニング
機械学習を用いて、より高度な解析も実現。Pythonを前提とした訓練済みモデルやディープラーニングのフレームワークも、 RStudioから簡単に利用可能。
◆電子版が発行されました
◆詳細は、森北出版Webサイトにて
【目次】
第1章 Rによる日本語テキスト解析の基礎
1.1 ファイルのダウンロードと読み込み
1.2 日本語形態素解析
1.3 ワードクラウド
1.4 ネットワークグラフ
第2章 センチメント分析
2.1 日本語極性辞書
2.2 テキストを文で区切る
2.3 感情極性値辞書の適用
2.4 感情極性値の時系列
第3章 構造的トピックモデル
3.1 トピックの分析方法
3.2 総理大臣所信表明演説の解析
3.3 ストップワードの削除
3.4 stmパッケージのためのデータ変換
3.5 stmパッケージによるトピック数の推定
3.6 トピックモデルの実行
3.7 夏目漱石『こころ』の解析
3.8 topicmodelsパッケージによるトピックモデル
3.9 ldatuningパッケージによるトピック数の推定
3.10 stm パッケージによるトピックモデル
第4章 Twitter投稿テキストの評価
4.1 API とは
4.2 Twitter APIの利用
4.3 ツイートの取得と前処理
4.4 形態素解析の実行
4.5 ggwordcloudパッケージによるワードクラウドの作図
4.6 ネットワークグラフ
4.7 ツイートの内容判定
4.8 ユーザーのグループ化
4.9 投稿者のプロフィールの極性比較
第5章 機械学習による予測
5.1 Twitter日本語評判分析データセット
5.2 ツイートの収集
5.3 ツイートの内容を予測するモデル
5.4 正則
5.5 glmnetパッケージによる回帰分析
5.6 機械学習の作業ルーティン
5.7 ランダムフォレスト
第6章 単語分散表現
6.1 単語ベクトル
6.2 単語分散表現
第7章 RからPythonライブラリを実行
7.1 訓練済み単語分散表現
7.2 PythonをRから利用するためのreticulate パッケージ
7.3 keras パッケージによるディープラーニング
補 遺
A.1 stringiパッケージ
A.2 udpipeパッケージ
A.3 udpipeによるトピックモデル
A.4 文章の重要度判定
A.5 RMeCabを活用する
A.6 テキストデータ取得に便利なパッケージ
参考文献
索 引
↓全て表示↑少なく表示
内容サンプル


目次
第1章 Rによる日本語テキスト解析の基礎
第2章 センチメント分析
第3章 構造的トピックモデル
第4章 Twitter投稿テキストの評価
第5章 機械学習による予測
第6章 単語分散表現
第7章 RからPythonライブラリを実行
第2章 センチメント分析
第3章 構造的トピックモデル
第4章 Twitter投稿テキストの評価
第5章 機械学習による予測
第6章 単語分散表現
第7章 RからPythonライブラリを実行
Users Voice
内容サンプル


著者略歴
石田基広(イシダモトヒロ)
1989年東京都立大学大学院人文科学研究科修士課程修了。1991年東京都立大学大学院人文科学研究科博士課程中退、広島大学文学部助手。1994年徳島大学総合科学部講師。1996年徳島大学総合科学部助教授。2008年徳島大学総合科学部准教授。2012年徳島大学大学院ソシオ・アーツ・アンド・サイエンス研究部教授。2017年徳島大学大学院社会産業理工学研究部教授(本データはこの書籍が刊行された当時に掲載されていたものです)
1989年東京都立大学大学院人文科学研究科修士課程修了。1991年東京都立大学大学院人文科学研究科博士課程中退、広島大学文学部助手。1994年徳島大学総合科学部講師。1996年徳島大学総合科学部助教授。2008年徳島大学総合科学部准教授。2012年徳島大学大学院ソシオ・アーツ・アンド・サイエンス研究部教授。2017年徳島大学大学院社会産業理工学研究部教授(本データはこの書籍が刊行された当時に掲載されていたものです)
↓全て表示↑少なく表示
RとShinyで作るWebアプリケーション

本書ではRのパッケージであるShinyを使ってWebアプリケーションを作る方法を解説しています。開発環境の構築やShinyの基礎から、具体的なアプリケーションの作成・公開まで丁寧に解説した1冊です。
※この商品は固定レイアウトで作成されており、タブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。
※この商品は固定レイアウトで作成されており、タブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。
内容サンプル


目次
01 RとShinyの導入
02 Shinyの基礎講座
03 回帰・分類・クラスタリングを行うShinyアプリケーション
04 地図と連携させたShinyアプリケーション
05 GoogleアナリティクスAPIを使ったShinyアプリケーション
06 Shinyアプリケーションを公開する
07 Shiny Tips
APPENDIX 分析手法
02 Shinyの基礎講座
03 回帰・分類・クラスタリングを行うShinyアプリケーション
04 地図と連携させたShinyアプリケーション
05 GoogleアナリティクスAPIを使ったShinyアプリケーション
06 Shinyアプリケーションを公開する
07 Shiny Tips
APPENDIX 分析手法
↓全て表示↑少なく表示
Users Voice
内容サンプル
R言語の本 最新・高評価のおすすめの5冊
以下が「R言語の本」最新・高評価のおすすめの5冊詳細です。
(2026/01/30 12:10 更新)
| Rank | 製品 | 価格 |
|---|---|---|
1 |  | |
2 |  | |
3 |  | |
4 |  | |
5 |  |
自然科学研究のためのR入門―再現可能なレポート執筆実践― (Wonderful R 4)

近年,Rなどのオープンソースのデータ解析環境が整ってきており,これらを活用することで,実験・測定・調査を行った結果に対して,研究者自身の手で高度な分析手法を適用できるようになった。
しかし,自然科学研究の多様化に伴い,研究者が扱わなければいけないデータの種類や量は増える一方である。また,データ解析手順も複雑化している。そのため自然科学系の実験分野においても,データ解析の再現性の重要性は高まっている。
Rでは解析の再現性を保証する方法としてRMarkdownが広く活用されている。その方法は本シリーズ第3巻『再現可能性のすゝめ』で詳しく解説されているが,本書はその実践集である。自然科学分野で主に取り扱うデータを想定した上で,RおよびRStudioを活用して,実験ノートやレポートをまとめあげる方法を,本書では具体例をあげつつ詳しく説明している。
しかし,自然科学研究の多様化に伴い,研究者が扱わなければいけないデータの種類や量は増える一方である。また,データ解析手順も複雑化している。そのため自然科学系の実験分野においても,データ解析の再現性の重要性は高まっている。
Rでは解析の再現性を保証する方法としてRMarkdownが広く活用されている。その方法は本シリーズ第3巻『再現可能性のすゝめ』で詳しく解説されているが,本書はその実践集である。自然科学分野で主に取り扱うデータを想定した上で,RおよびRStudioを活用して,実験ノートやレポートをまとめあげる方法を,本書では具体例をあげつつ詳しく説明している。
目次
Chapter 1 はじめに
1.1 RMarkdown
1.2 sessioninfoによるバージョン情報の確認
1.3 プロジェクトの作成
1.4 本章のまとめと参考文献
Chapter 2 基本的な統計モデリング―要因と目的変数の関係解析(1)
2.1 データの読み込み・概観チェック・集計・可視化
2.2 【レポート例2-1】
2.3 検定・相関解析
2.4 統計モデリング第一歩
2.5 【レポート例2-2】
2.6 本章のまとめと参考文献
Chapter 3 発展的な統計モデリング―要因と目的変数の関係解析(2)
3.1 データの読み込み・集計・可視化
3.2 【レポート例3-1】
3.3 検定
3.4 統計モデリング
3.5 【レポート例3-2】
3.6 本章のまとめと参考文献
Chapter 4 実験計画法と分散分析
4.1 一元配置分散分析―One-way ANOVAによる精製カラムの検討
4.2 二元配置分散分析―Two-way ANOVAによる検出器の検討
4.3 【レポート例4-1】
4.4 直交表を使った分散分析―多数の因子がある場合の組み合わせ効率化:注入口条件の最適化
4.5 分析法の検証
4.6 【レポート例4-2】
4.7 本章のまとめと参考文献
Chapter 5 機械学習―代謝産物の変動解析を例に
5.1 データの読み込み・加工・可視化・検定
5.2 機械学習による判別分析
5.3 変数重要度が上位の因子によるpathway解析および機能解析の準備
5.4 【レポート例5】
5.5 本章のまとめと参考文献
Chapter 6 実践 レポート作成―化学物質の分子記述子と物性の関係解析を例に
6.1 ファイル作成・YAML記述
6.2 本文の記述とデータの読み込み
6.3 機械学習モデル
6.4 バリデーションセットを用いた精度の検証
6.5 変数重要度
6.6 実行環境・引用文献
6.7 本章のまとめと参考文献
1.1 RMarkdown
1.2 sessioninfoによるバージョン情報の確認
1.3 プロジェクトの作成
1.4 本章のまとめと参考文献
Chapter 2 基本的な統計モデリング―要因と目的変数の関係解析(1)
2.1 データの読み込み・概観チェック・集計・可視化
2.2 【レポート例2-1】
2.3 検定・相関解析
2.4 統計モデリング第一歩
2.5 【レポート例2-2】
2.6 本章のまとめと参考文献
Chapter 3 発展的な統計モデリング―要因と目的変数の関係解析(2)
3.1 データの読み込み・集計・可視化
3.2 【レポート例3-1】
3.3 検定
3.4 統計モデリング
3.5 【レポート例3-2】
3.6 本章のまとめと参考文献
Chapter 4 実験計画法と分散分析
4.1 一元配置分散分析―One-way ANOVAによる精製カラムの検討
4.2 二元配置分散分析―Two-way ANOVAによる検出器の検討
4.3 【レポート例4-1】
4.4 直交表を使った分散分析―多数の因子がある場合の組み合わせ効率化:注入口条件の最適化
4.5 分析法の検証
4.6 【レポート例4-2】
4.7 本章のまとめと参考文献
Chapter 5 機械学習―代謝産物の変動解析を例に
5.1 データの読み込み・加工・可視化・検定
5.2 機械学習による判別分析
5.3 変数重要度が上位の因子によるpathway解析および機能解析の準備
5.4 【レポート例5】
5.5 本章のまとめと参考文献
Chapter 6 実践 レポート作成―化学物質の分子記述子と物性の関係解析を例に
6.1 ファイル作成・YAML記述
6.2 本文の記述とデータの読み込み
6.3 機械学習モデル
6.4 バリデーションセットを用いた精度の検証
6.5 変数重要度
6.6 実行環境・引用文献
6.7 本章のまとめと参考文献
↓全て表示↑少なく表示
Users Voice
著者略歴
江口哲史(エグチアキフミ)
2013年愛媛大学理工学研究科博士後期課程修了。日本学術振興会特別研究員などを経て、千葉大学予防医学センター助教。専門、環境分析化学
石田基広(イシダモトヒロ)
1989年東京都立大学大学院博士後期課程中退。現在、徳島大学総合科学部教授。専攻、テキストマイニング(本データはこの書籍が刊行された当時に掲載されていたものです)
2013年愛媛大学理工学研究科博士後期課程修了。日本学術振興会特別研究員などを経て、千葉大学予防医学センター助教。専門、環境分析化学
石田基広(イシダモトヒロ)
1989年東京都立大学大学院博士後期課程中退。現在、徳島大学総合科学部教授。専攻、テキストマイニング(本データはこの書籍が刊行された当時に掲載されていたものです)
RとPythonで学ぶ[実践的]データサイエンス&機械学習【増補改訂版】

(概要)
本書は野村総研で開催されている全社コンサルタントとエンジニア向けのビジネスアナリティクス講座をベースにした書籍の増補改訂版です。具体的なサンプルを元にデータ分析とモデリングを進めるところが特徴です。また、統計解析や機械学習では「何ができないか」や、ビジネスデータの分析時に陥りがちな「落とし穴」など、現場で活用できる実践的な解説も満載です。改訂にあたっては、全編を最新のシステム環境に合わせてまとめ直しました。環境設定についてはコラムでも細やかにフォローし、データサイエンスと機械学習の基礎が学びやすいように進化しています。
(こんな方におすすめ)
・データ分析・統計解析や機械学習について知りたい方
・データサイエンティストになりたい方
(目次)
第1章:データサイエンス入門
1.1:データサイエンスの基本
1.2:データサイエンスの実践
第2章:RとPython
2.1:RとPython
2.2:R入門
2.3:Python入門
2.4:RとPythonの実行例の比較
第3章:データ分析と基本的なモデリング
3.1:データの特徴を捉える
3.2:データからモデルを作る
3.3:モデルを評価する
第4章:実践的なモデリング
4.1:モデリングの準備
4.2:データの加工
4.3:モデリングの手法
4.4:因果推論
第5章:機械学習とディープラーニング
5.1:機械学習の基本とその実行
5.2:機械学習アルゴリズムの例
5.3:機械学習の手順
5.4:機械学習の実践
5.5:ディープラーニング
本書は野村総研で開催されている全社コンサルタントとエンジニア向けのビジネスアナリティクス講座をベースにした書籍の増補改訂版です。具体的なサンプルを元にデータ分析とモデリングを進めるところが特徴です。また、統計解析や機械学習では「何ができないか」や、ビジネスデータの分析時に陥りがちな「落とし穴」など、現場で活用できる実践的な解説も満載です。改訂にあたっては、全編を最新のシステム環境に合わせてまとめ直しました。環境設定についてはコラムでも細やかにフォローし、データサイエンスと機械学習の基礎が学びやすいように進化しています。
(こんな方におすすめ)
・データ分析・統計解析や機械学習について知りたい方
・データサイエンティストになりたい方
(目次)
第1章:データサイエンス入門
1.1:データサイエンスの基本
1.2:データサイエンスの実践
第2章:RとPython
2.1:RとPython
2.2:R入門
2.3:Python入門
2.4:RとPythonの実行例の比較
第3章:データ分析と基本的なモデリング
3.1:データの特徴を捉える
3.2:データからモデルを作る
3.3:モデルを評価する
第4章:実践的なモデリング
4.1:モデリングの準備
4.2:データの加工
4.3:モデリングの手法
4.4:因果推論
第5章:機械学習とディープラーニング
5.1:機械学習の基本とその実行
5.2:機械学習アルゴリズムの例
5.3:機械学習の手順
5.4:機械学習の実践
5.5:ディープラーニング
↓全て表示↑少なく表示
内容サンプル


目次
第1章:データサイエンス入門
1.1:データサイエンスの基本
1.1.1:データサイエンスの重要性
1.1.2:データサイエンスの定義とその歴史
1.1.3:データサイエンスにおけるモデリング
1.1.4:データサイエンスとその関連領域
1.2:データサイエンスの実践
1.2.1:データサイエンスのプロセスとタスク
1.2.2:データサイエンスの実践に必要なツール
1.2.3:データサイエンスの実践に必要なスキル
1.2.4:データサイエンスの限界と課題
コラム:ビジネス活用における留意点
第2章:RとPython
2.1:RとPython
2.1.1:RとPythonの比較
2.2:R入門
2.2.1:Rの概要
2.2.2:Rの文法
2.2.3:データ構造と制御構造
2.3:Python入門
2.3.1:Pythonの概要
2.3.2:Pythonの文法
2.3.3:Pythonでのプログラミング
2.3.4:NumPyとpandas
2.4:RとPythonの実行例の比較
2.4.1:簡単な分析の実行例
第3章:データ分析と基本的なモデリング
3.1:データの特徴を捉える
3.1.1:分布の形を捉える ─ ビジュアルでの確認
3.1.2:要約統計量を算出する ─ 代表値とばらつき
3.1.3:関連性を把握する ─ 相関係数の使い方と意味
3.1.4:Rを使った相関分析 ─ 自治体のデータを使った例
3.1.5:確立分布とその利用 ─ 理論と実際の考え方
3.2:データからモデルを作る
3.2.1:目的変数と説明変数 ─ 説明と予測の「向き」
3.2.2:簡単な線形回帰モデル ─ Rによる実行と結果
3.2.3:ダミー変数を使ったモデル ─ グループ間の差異を分析
3.2.4:複雑な線形回帰モデル ─ 交互作用,モデル間の比較
3.2.5:線形回帰の仕組みと最小二乗法
3.3:モデルを評価する
3.3.1:モデルを評価するための観点
3.3.2:この結果は偶然ではないのか? ─ 有意確率と有意差検定
3.3.3:モデルはデータに当てはまっているか? ─ フィッティングと決定係数
3.3.4:モデルは複雑すぎないか? ─ オーバーフィッティングと予測精度
3.3.5:残差の分布 ─ 線形回帰モデルと診断プロット
3.3.6:説明変数同士の相関 ─ 多重共線性
3.3.7:標準偏回帰係数
第4章:実践的なモデリング
4.1:モデリングの準備
4.1.1:データの準備と加工
4.1.2:分析とモデリングの手法
4.2:データの加工
4.2.1:データのクレンジング
4.2.2:カテゴリ変数の加工
4.2.3:数値変数の加工とスケーリング
4.2.4:分布の形を変える ─ 対数変換とロジット変換
4.2.5:欠損値の処理
4.2.6:外れ値の処理
4.3:モデリングの手法
4.3.1:グループに分ける ─ クラスタリング
4.3.2:指標を集約する ─ 因子分析と主成分分析
4.3.3:一般化線形モデル(GLM)とステップワイズ法
4.3.4:2値データを目的変数とする分析 ─ ロジスティック回帰
4.3.5:セグメントの抽出とその特徴の分析 ─ 決定木
4.4:因果推論
4.4.1:データから因果関係を明らかにする ─ 統計的因果推論
4.4.2:因果の有無の検証
4.4.3:因果効果の推定
4.4.4:因果関係の定式化 ─ 構造方程式モデリング
4.4.5:因果関係の定式化 ─ 構造的因果モデル
4.4.6:因果関係の定式化 ─ ベイズ統計モデリング
4.4.7:因果の探索
4.4.8:因果関係に基づく変数選択
第5章:機械学習とディープラーニング
5.1:機械学習の基本とその実行
5.1.1:機械学習の基本
5.1.2:機械学習ライブラリの活用 ─ scikit-learn
5.1.3:機械学習の実行(教師あり学習)
5.1.4:機械学習の実行(教師なし学習)
5.1.5:スケーリングの実行(標準化・正規化)
5.1.6:次元の削減(主成分分析)
コラム:機械学習と強化学習
5.2:機械学習アルゴリズムの例
5.2.1:k近傍法
5.2.2:ランダムフォレスト
5.2.3:ロジスティック回帰とリッジ回帰
5.2.4:サポートベクターマシン(SVM)
5.3:機械学習の手順
5.3.1:機械学習の主要な手順
5.3.2:ホールドアウト法による実行
5.3.3:クロスバリデーションとグリッドサーチ
5.3.4:閾値の調整
5.3.5:特徴量の重要度と部分従属プロット
5.4:機械学習の実践
5.4.1:データの準備に関わる問題
5.4.2:特徴抽出と特徴ベクトル
5.4.3:機械学習の実行例
5.5:ディープラーニング
5.5.1:ニューラルネットワーク
5.5.2:ディープラーニングを支える技術
5.5.3:ディープラーニング・フレームワーク
5.5.4:ディープラーニングの実行
5.5.5:生成モデル
1.1:データサイエンスの基本
1.1.1:データサイエンスの重要性
1.1.2:データサイエンスの定義とその歴史
1.1.3:データサイエンスにおけるモデリング
1.1.4:データサイエンスとその関連領域
1.2:データサイエンスの実践
1.2.1:データサイエンスのプロセスとタスク
1.2.2:データサイエンスの実践に必要なツール
1.2.3:データサイエンスの実践に必要なスキル
1.2.4:データサイエンスの限界と課題
コラム:ビジネス活用における留意点
第2章:RとPython
2.1:RとPython
2.1.1:RとPythonの比較
2.2:R入門
2.2.1:Rの概要
2.2.2:Rの文法
2.2.3:データ構造と制御構造
2.3:Python入門
2.3.1:Pythonの概要
2.3.2:Pythonの文法
2.3.3:Pythonでのプログラミング
2.3.4:NumPyとpandas
2.4:RとPythonの実行例の比較
2.4.1:簡単な分析の実行例
第3章:データ分析と基本的なモデリング
3.1:データの特徴を捉える
3.1.1:分布の形を捉える ─ ビジュアルでの確認
3.1.2:要約統計量を算出する ─ 代表値とばらつき
3.1.3:関連性を把握する ─ 相関係数の使い方と意味
3.1.4:Rを使った相関分析 ─ 自治体のデータを使った例
3.1.5:確立分布とその利用 ─ 理論と実際の考え方
3.2:データからモデルを作る
3.2.1:目的変数と説明変数 ─ 説明と予測の「向き」
3.2.2:簡単な線形回帰モデル ─ Rによる実行と結果
3.2.3:ダミー変数を使ったモデル ─ グループ間の差異を分析
3.2.4:複雑な線形回帰モデル ─ 交互作用,モデル間の比較
3.2.5:線形回帰の仕組みと最小二乗法
3.3:モデルを評価する
3.3.1:モデルを評価するための観点
3.3.2:この結果は偶然ではないのか? ─ 有意確率と有意差検定
3.3.3:モデルはデータに当てはまっているか? ─ フィッティングと決定係数
3.3.4:モデルは複雑すぎないか? ─ オーバーフィッティングと予測精度
3.3.5:残差の分布 ─ 線形回帰モデルと診断プロット
3.3.6:説明変数同士の相関 ─ 多重共線性
3.3.7:標準偏回帰係数
第4章:実践的なモデリング
4.1:モデリングの準備
4.1.1:データの準備と加工
4.1.2:分析とモデリングの手法
4.2:データの加工
4.2.1:データのクレンジング
4.2.2:カテゴリ変数の加工
4.2.3:数値変数の加工とスケーリング
4.2.4:分布の形を変える ─ 対数変換とロジット変換
4.2.5:欠損値の処理
4.2.6:外れ値の処理
4.3:モデリングの手法
4.3.1:グループに分ける ─ クラスタリング
4.3.2:指標を集約する ─ 因子分析と主成分分析
4.3.3:一般化線形モデル(GLM)とステップワイズ法
4.3.4:2値データを目的変数とする分析 ─ ロジスティック回帰
4.3.5:セグメントの抽出とその特徴の分析 ─ 決定木
4.4:因果推論
4.4.1:データから因果関係を明らかにする ─ 統計的因果推論
4.4.2:因果の有無の検証
4.4.3:因果効果の推定
4.4.4:因果関係の定式化 ─ 構造方程式モデリング
4.4.5:因果関係の定式化 ─ 構造的因果モデル
4.4.6:因果関係の定式化 ─ ベイズ統計モデリング
4.4.7:因果の探索
4.4.8:因果関係に基づく変数選択
第5章:機械学習とディープラーニング
5.1:機械学習の基本とその実行
5.1.1:機械学習の基本
5.1.2:機械学習ライブラリの活用 ─ scikit-learn
5.1.3:機械学習の実行(教師あり学習)
5.1.4:機械学習の実行(教師なし学習)
5.1.5:スケーリングの実行(標準化・正規化)
5.1.6:次元の削減(主成分分析)
コラム:機械学習と強化学習
5.2:機械学習アルゴリズムの例
5.2.1:k近傍法
5.2.2:ランダムフォレスト
5.2.3:ロジスティック回帰とリッジ回帰
5.2.4:サポートベクターマシン(SVM)
5.3:機械学習の手順
5.3.1:機械学習の主要な手順
5.3.2:ホールドアウト法による実行
5.3.3:クロスバリデーションとグリッドサーチ
5.3.4:閾値の調整
5.3.5:特徴量の重要度と部分従属プロット
5.4:機械学習の実践
5.4.1:データの準備に関わる問題
5.4.2:特徴抽出と特徴ベクトル
5.4.3:機械学習の実行例
5.5:ディープラーニング
5.5.1:ニューラルネットワーク
5.5.2:ディープラーニングを支える技術
5.5.3:ディープラーニング・フレームワーク
5.5.4:ディープラーニングの実行
5.5.5:生成モデル
↓全て表示↑少なく表示
Users Voice
内容サンプル


Rによる機械学習[第3版]

絶え間なく更新されるベストプラクティスが
「ベスト」であり続けるための基礎技術のすべて
【本書の内容】
本書は
Brett Lantz, "Machine Learning with R - Third Edition",
Packt Publishing, 2019
の邦訳版です。
本書は「機械学習」で語られることの多い手法(最近傍法や回帰法、ナイーブベイズ
や決定木を使った分類法)を網羅し、それぞれの意味や成立条件を解説します。
といっても、ゴリゴリの数式だけを使うわけではなく、既存のデータを使用し、
それら手法によって解析した結果、どのようなグラフが表示されるか、を
手取り足取りで解説してくれます。
ですから、機械学習を構成するさまざまな手法を、実際に使えるレベルで理解できる
ようになります。
そのため、自身が関わるプロジェクトにおいて、どの手法がベストプラクティスと
なるのか、無意味な分析・解析を避ける勘所がわかるようになるでしょう。
「機械学習」を学んだものの「もやもや」に付きまとわれているエンジニアに
よく効く一冊です。
【本書のポイント】
・「機械学習」と呼ばれる手法を網羅
・手法を構成する手続きやその前準備を微細に解説
・各手法のメリットとデメリットも紹介
・実際に手を動かすことで各種手法を正しく利用できるようになる
【読者が得られること】
・機械学習とその派生手法のモデルを頭の中に構築できる
・機械学習を成立させるさまざまな手法に精通できる
・プロジェクトで真に必要な手法がわかる
・(ついでに)R言語(4.x系)も習得できる
【著者について】
・Brett Lantz(ブレット・ランツ)
社会学者として教育を受けた著者は、人間の行動を理解するために10年以上に
わたってイノベーティブなデータ手法を活用してきた。
DataCampの講師であり、世界中の機械学習カンファレンスやワークショップで
たびたび講演を行っている。
※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。
※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。
※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。
※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。
「ベスト」であり続けるための基礎技術のすべて
【本書の内容】
本書は
Brett Lantz, "Machine Learning with R - Third Edition",
Packt Publishing, 2019
の邦訳版です。
本書は「機械学習」で語られることの多い手法(最近傍法や回帰法、ナイーブベイズ
や決定木を使った分類法)を網羅し、それぞれの意味や成立条件を解説します。
といっても、ゴリゴリの数式だけを使うわけではなく、既存のデータを使用し、
それら手法によって解析した結果、どのようなグラフが表示されるか、を
手取り足取りで解説してくれます。
ですから、機械学習を構成するさまざまな手法を、実際に使えるレベルで理解できる
ようになります。
そのため、自身が関わるプロジェクトにおいて、どの手法がベストプラクティスと
なるのか、無意味な分析・解析を避ける勘所がわかるようになるでしょう。
「機械学習」を学んだものの「もやもや」に付きまとわれているエンジニアに
よく効く一冊です。
【本書のポイント】
・「機械学習」と呼ばれる手法を網羅
・手法を構成する手続きやその前準備を微細に解説
・各手法のメリットとデメリットも紹介
・実際に手を動かすことで各種手法を正しく利用できるようになる
【読者が得られること】
・機械学習とその派生手法のモデルを頭の中に構築できる
・機械学習を成立させるさまざまな手法に精通できる
・プロジェクトで真に必要な手法がわかる
・(ついでに)R言語(4.x系)も習得できる
【著者について】
・Brett Lantz(ブレット・ランツ)
社会学者として教育を受けた著者は、人間の行動を理解するために10年以上に
わたってイノベーティブなデータ手法を活用してきた。
DataCampの講師であり、世界中の機械学習カンファレンスやワークショップで
たびたび講演を行っている。
※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。
※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。
※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。
※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。
↓全て表示↑少なく表示
内容サンプル


目次
第1章 機械学習入門
1.1 機械学習の起源
1.2 機械学習の利用と乱用
1.3 機械はどのように学習するか
1.4 実際の機械学習
1.5 Rによる機械学習
1.6 まとめ
第2章 データを管理し、理解する
2.1 Rのデータ構造
2.2 Rでのデータの管理
2.3 データを調べて理解する
2.4 まとめ
第3章 怠惰学習―最近傍法を使った分類
3.1 最近傍法分類を理解する
3.2 例:k最近傍法を使って乳がんを診断する
3.3 まとめ
第4章 確率論的学習―ナイーブベイズを使った分類
4.1 ナイーブベイズを理解する
4.2 例:ナイーブベイズを使ってSMSスパムをフィルタリングする
4.3 まとめ
第5章 分割統治―決定木と分類ルールに基づく分類
5.1 決定木を理解する
5.2 例:C5.0の決定木を使ってあぶない融資を特定する
5.3 分類ルールを理解する
5.4 例:分類ルール学習器を使って毒キノコを識別する
5.5 まとめ
第6章 数値データを予測する―回帰法
6.1 回帰を理解する
6.2 例:線形回帰を使って医療費を予測する
6.3 回帰木とモデル木を理解する
6.4 例:回帰木とモデル木を使ってワインの品質を予測する
6.5 まとめ
第7章 ブラックボックス手法―ニューラルネットワークとサポートベクトルマシン
7.1 ニューラルネットワークを理解する
7.2 例:人工ニューラルネットワークを使ってコンクリートの強度をモデル化する
7.3 サポートベクトルマシンを理解する
7.4 例:SVMを使って文字を認識する
7.5 まとめ
第8章 パターン検出―相関ルールを使ったバスケット分析
8.1 相関ルールを理解する
8.2 例:相関ルールを使って頻繁に購入される商品を特定する
8.3 まとめ
第9章 データのグループを特定する―k-means法
9.1 クラスタリングを理解する
9.2 例:k-means法を使ってマーケティングセグメントを特定する
9.3 まとめ
第10章 モデルの性能を評価する
10.1 分類の性能を計測する
10.2 将来の性能を推定する
10.3 まとめ
第11章 モデルの性能を改善する
11.1 定番のモデルの性能を向上させる
11.2 メタ学習でモデルの性能を改善する
11.3 まとめ
第12章 機械学習の専門的なトピック
12.1 現実のデータの管理と前処理
12.2 オンラインデータとオンラインサービスの操作
12.3 問題領域固有のデータを操作する
12.4 Rの性能を向上させる
12.5 まとめ
1.1 機械学習の起源
1.2 機械学習の利用と乱用
1.3 機械はどのように学習するか
1.4 実際の機械学習
1.5 Rによる機械学習
1.6 まとめ
第2章 データを管理し、理解する
2.1 Rのデータ構造
2.2 Rでのデータの管理
2.3 データを調べて理解する
2.4 まとめ
第3章 怠惰学習―最近傍法を使った分類
3.1 最近傍法分類を理解する
3.2 例:k最近傍法を使って乳がんを診断する
3.3 まとめ
第4章 確率論的学習―ナイーブベイズを使った分類
4.1 ナイーブベイズを理解する
4.2 例:ナイーブベイズを使ってSMSスパムをフィルタリングする
4.3 まとめ
第5章 分割統治―決定木と分類ルールに基づく分類
5.1 決定木を理解する
5.2 例:C5.0の決定木を使ってあぶない融資を特定する
5.3 分類ルールを理解する
5.4 例:分類ルール学習器を使って毒キノコを識別する
5.5 まとめ
第6章 数値データを予測する―回帰法
6.1 回帰を理解する
6.2 例:線形回帰を使って医療費を予測する
6.3 回帰木とモデル木を理解する
6.4 例:回帰木とモデル木を使ってワインの品質を予測する
6.5 まとめ
第7章 ブラックボックス手法―ニューラルネットワークとサポートベクトルマシン
7.1 ニューラルネットワークを理解する
7.2 例:人工ニューラルネットワークを使ってコンクリートの強度をモデル化する
7.3 サポートベクトルマシンを理解する
7.4 例:SVMを使って文字を認識する
7.5 まとめ
第8章 パターン検出―相関ルールを使ったバスケット分析
8.1 相関ルールを理解する
8.2 例:相関ルールを使って頻繁に購入される商品を特定する
8.3 まとめ
第9章 データのグループを特定する―k-means法
9.1 クラスタリングを理解する
9.2 例:k-means法を使ってマーケティングセグメントを特定する
9.3 まとめ
第10章 モデルの性能を評価する
10.1 分類の性能を計測する
10.2 将来の性能を推定する
10.3 まとめ
第11章 モデルの性能を改善する
11.1 定番のモデルの性能を向上させる
11.2 メタ学習でモデルの性能を改善する
11.3 まとめ
第12章 機械学習の専門的なトピック
12.1 現実のデータの管理と前処理
12.2 オンラインデータとオンラインサービスの操作
12.3 問題領域固有のデータを操作する
12.4 Rの性能を向上させる
12.5 まとめ
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
ランツ,ブレット(Lantz,Brett)
社会学者。DataCampの講師であり、世界中の機械学習カンファレンスやワークショップでたびたび講演を行っている(本データはこの書籍が刊行された当時に掲載されていたものです)
社会学者。DataCampの講師であり、世界中の機械学習カンファレンスやワークショップでたびたび講演を行っている(本データはこの書籍が刊行された当時に掲載されていたものです)
実践Data Scienceシリーズ RとStanではじめる ベイズ統計モデリングによるデータ分析入門 (KS情報科学専...

実践Data Scienceシリーズ RとStanではじめる ベイズ統計モデリングによるデータ分析入門 (KS情報科学専門書)
(著)馬場真哉
発売日 2019/08/23
(著)馬場真哉
発売日 2019/08/23
総合評価
(2026/01/21 12:09時点)
「基本をより実践的に!」学べる新シリーズの第一弾は、「統計モデリングの世界」へのファーストブック。基礎から学べる超入門!・チュートリアル形式だから、すぐに実践できる!・統計、確率、ベイズ推論、MCMCの基本事項から、やさしくサポート!・brmsやbayesplotなどのパッケージの使い方も、しっかり身につく!・一般化線形モデル(GLM)→一般化線形混合モデル(GLMM)→動的線形モデル(DLM)→動的一般化線形モデル(DGLM)を体系的に学べる!【本書のサポートページ】https://logics-of-blue.com/r-stan-bayesian-model-intro-book-support/ 【実践Data Scienceシリーズ】 「基本をより実践的に!」を合言葉に、データサイエンスで用いられる各種手法の基本を、プログラミングの実装とともに解説していきます。はじめて学ぶ大学生、大学院生、ソフトウェアエンジニアに向けた注目の新シリーズです。【主な内容】1部 【理論編】ベイズ統計モデリングの基本 1.はじめよう! ベイズ統計モデリング 2.統計学の基本 3.確率の基本 4.確率分布の基本 5.統計モデルの基本 6.ベイズ推論の基本 7.MCMCの基本/2部 【基礎編】RとStanによるデータ分析 1.Rの基本 2.データの要約 3.ggplot2によるデータの可視化 4.Stanの基本 5.MCMCの結果の評価 6.Stanコーディングの詳細/3部 【実践編】一般化線形モデル 1.一般化線形モデルの基本 2.単回帰モデル 3.モデルを用いた予測 4.デザイン行列を用いた一般化線形モデルの推定 5.brmsの使い方 6.ダミー変数と分散分析モデル 7.正規線形モデル 8.ポアソン回帰モデル 9.ロジスティック回帰モデル 10.交互作用/4部 【応用編】一般化線形混合モデル 1.階層ベイズモデルと一般化線形混合モデルの基本 2.ランダム切片モデル 3.ランダム係数モデル/5部 【応用編】状態空間モデル 1.時系列分析と状態空間モデルの基本 2.ローカルレベルモデル 3.状態空間モデルによる予測と補間 4.時変係数モデル 5.トレンドの構造 6.周期性のモデル化 7.自己回帰モデルとその周辺 8.動的一般化線形モデル:二項分布を仮定した例 9.動的一般化線形モデル:ポアソン分布を仮定した例
↓全て表示↑少なく表示
内容サンプル


目次
第1部 【理論編】ベイズ統計モデリングの基本
第1章 はじめよう! ベイズ統計モデリング
第2章 統計学の基本
第3章 確率の基本
第4章 確率分布の基本
第5章 統計モデルの基本
第6章 ベイズ推論の基本
第7章 MCMCの基本
第2部 【基礎編】RとStanによるデータ分析
第1章 Rの基本
第2章 データの要約
第3章 ggplot2によるデータの可視化
第4章 Stanの基本
第5章 MCMCの結果の評価
第6章 Stanコーディングの詳細
第3部 【実践編】一般化線形モデル
第1章 一般化線形モデルの基本
第2章 単回帰モデル
第3章 モデルを用いた予測
第4章 デザイン行列を用いた一般化線形モデルの推定
第5章 brmsの使い方
第6章 ダミー変数と分散分析モデル
第7章 正規線形モデル
第8章 ポアソン回帰モデル
第9章 ロジスティック回帰モデル
第10章 交互作用
第4部 【応用編】一般化線形混合モデル
第1章 階層ベイズモデルと一般化線形混合モデルの基本
第2章 ランダム切片モデル
第3章 ランダム係数モデル
第5部 【応用編】状態空間モデル
第1章 時系列分析と状態空間モデルの基本
第2章 ローカルレベルモデル
第3章 状態空間モデルによる予測と補間
第4章 時変係数モデル
第5章 トレンドの構造
第6章 周期性のモデル化
第7章 自己回帰モデルとその周辺
第8章 動的一般化線形モデル:二項分布を仮定した例
第9章 動的一般化線形モデル:ポアソン分布を仮定した例
第1章 はじめよう! ベイズ統計モデリング
第2章 統計学の基本
第3章 確率の基本
第4章 確率分布の基本
第5章 統計モデルの基本
第6章 ベイズ推論の基本
第7章 MCMCの基本
第2部 【基礎編】RとStanによるデータ分析
第1章 Rの基本
第2章 データの要約
第3章 ggplot2によるデータの可視化
第4章 Stanの基本
第5章 MCMCの結果の評価
第6章 Stanコーディングの詳細
第3部 【実践編】一般化線形モデル
第1章 一般化線形モデルの基本
第2章 単回帰モデル
第3章 モデルを用いた予測
第4章 デザイン行列を用いた一般化線形モデルの推定
第5章 brmsの使い方
第6章 ダミー変数と分散分析モデル
第7章 正規線形モデル
第8章 ポアソン回帰モデル
第9章 ロジスティック回帰モデル
第10章 交互作用
第4部 【応用編】一般化線形混合モデル
第1章 階層ベイズモデルと一般化線形混合モデルの基本
第2章 ランダム切片モデル
第3章 ランダム係数モデル
第5部 【応用編】状態空間モデル
第1章 時系列分析と状態空間モデルの基本
第2章 ローカルレベルモデル
第3章 状態空間モデルによる予測と補間
第4章 時変係数モデル
第5章 トレンドの構造
第6章 周期性のモデル化
第7章 自己回帰モデルとその周辺
第8章 動的一般化線形モデル:二項分布を仮定した例
第9章 動的一般化線形モデル:ポアソン分布を仮定した例
↓全て表示↑少なく表示
Users Voice
内容サンプル


著者略歴
RとKerasによるディープラーニング

Pythonのディープラーニング用ライブラリKeras開発者のFrançois Cholletと、RStudio創設者兼CEO兼開発者としてRコミュニティで絶大な信頼を集めるJ. J. Allaireによる共著。
ディープラーニングを学びたいRユーザ向けに、まず概念を説明し、それを実装したサンプルを示すというスタイルで、実際にサンプルを動かしながら学ぶことができます。
ディープラーニングとはどんなものか、AIや機械学習との関連、なぜ重要性が増しているのかだけでなく、コンピュータビジョン、自然言語処理などの実用的な例題も扱います。
使い慣れたRを使ってディープラーニングについて学びたいというRユーザの期待に応える一冊です。
ディープラーニングを学びたいRユーザ向けに、まず概念を説明し、それを実装したサンプルを示すというスタイルで、実際にサンプルを動かしながら学ぶことができます。
ディープラーニングとはどんなものか、AIや機械学習との関連、なぜ重要性が増しているのかだけでなく、コンピュータビジョン、自然言語処理などの実用的な例題も扱います。
使い慣れたRを使ってディープラーニングについて学びたいというRユーザの期待に応える一冊です。
Users Voice
R言語の本「新書一覧(2021年、2022年刊行)」
IT技術・プログラミング言語は、最新情報のキャッチアップも非常に重要、すなわち新書は要チェック。
ということで、2020年以降に発売したR言語の本の新書一覧(発売日の新しい順)が以下です。
(2026/01/30 12:10 更新)
| 製品 | 価格 |
|---|---|
 | |
 | |
 | |
 | |
 | |
改訂2版 RユーザのためのRStudio[実践]入門〜tidyverseによるモダンな分析フローの世界... 発売日 2021/05/31 松村 優哉, 湯谷 啓明, 紀ノ定 保礼, 前田 和寛 (技術評論社) 総合評価 | |
 | |
| |
| |
|
R言語の本「Kindle Unlimited 読み放題 人気本ランキング」
「Kindle Unlimited」は、Amazonの定額本読み放題サービス。
最近はKindle Unlimitedで読める本もどんどん増えており、雑誌、ビジネス書、実用書などは充実のラインナップ。
以下がKindle Unlimitedで読み放題となるR言語の本の一覧です。
30日無料体験も可能なので、読みたい本があれば体験期間で無料で読むことも可能です。
(2026/01/30 12:10 更新)
| Rank | 製品 | 価格 |
|---|---|---|
1 |  | 500円 |
関連:Python・データ解析系の本
以下ではRと同じくデータ解析・統計分析に有用なPythonと、機械学習・データ解析系の本をまとめています、合わせてのぞいて見てください。






いじょうでっす。
コメント